维度网讯,微软首席执行官萨提亚·纳德拉(Satya Nadella)阐明,许多企业在人工智能战略上忽视了一个关键点:真正的竞争并不在于选择哪个模型,而在于组织是否能够从自身所构建的系统中学习。
纳德拉所强调的核心概念是“学习循环”。这一机制指的是一个系统在每次使用时都能自我优化,并非通过软件升级,而是通过对运行过程中产生的事件进行捕获、分析并改进,从而不断提升性能。与之相对的是,目前大多数企业级人工智能应用并非如此运作。例如,企业在工作流中部署ChatGPT或类似模型,它能够回答问题,但当用户以略微不同的方式再次提出相同问题时,系统对企业具体的业务场景并无记忆。这意味着企业拥有的只是一个更智能的通用工具,而非一个具备学习能力的循环系统。
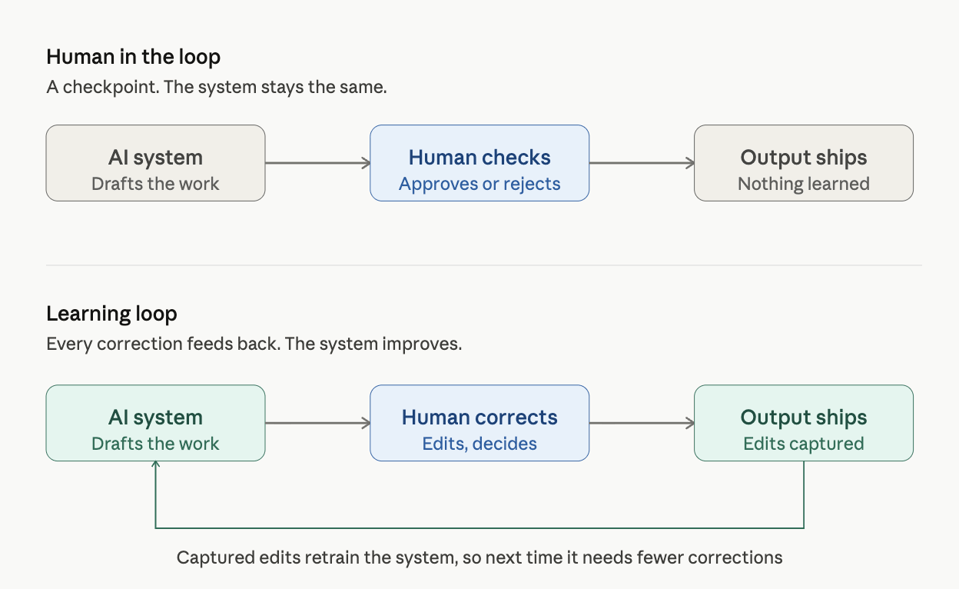
过去两年,业界普遍强调“人在回路中”的解决方案,即通过人工审核来批准人工智能的输出。纳德拉认为,这种方式只是一个检查点,而非真正的学习过程。企业并未因此改进系统,只是增加了人力成本来把控质量。他提出,如果组织不是单纯检查人工智能的输出,而是捕获每一次交互、每一次修正和每一次结果,并将这些反馈信息用于系统自身的迭代,使其在特定业务领域内变得更智能,这才构成了真正的学习循环。
纳德拉通过一个销售场景进行了具体说明。一个由AI代理起草销售提案的系统,如果没有学习循环,其起草的100份提案中可能有80份需要销售人员根据公司的定价模式或客户痛点进行编辑,且次月问题依旧。而在具备学习循环的系统中,系统会捕获每一次编辑行为。经过500份提案的学习,系统会掌握公司实际的销售逻辑,而非通用的流程。到第1000份提案时,几乎不需要编辑。企业由此构建了无法通过简单下载获得的专属知识产权。
纳德拉在相关的备忘录中指出,不应在模型选择上竞争,因为所有企业都能使用Claude、GPT和Gemini等模型。优势应来源于围绕模型构建的系统,而非模型本身的算力。微软的利益在于,它希望企业在其Azure平台上构建这些循环,包括进行微调、存储专有数据,并投入成本使切换变得困难。这一框架将竞争焦点从“谁拥有最好的模型”转向了“谁构建了最智能的系统”。
对于学习循环理论,行业内存在不同意见。OpenAI目前支持广泛的微调方法,但其更大的策略是不断改进基础模型,使其足够强大,从而无需复杂的循环。Anthropic则倾向于通过项目、检索工作流和宪法AI来治理,其微调主要限于较旧的Claude模型,更重视控制、安全与治理。开源路径通过LoRA和参数高效微调在Llama等模型上提供了独立性,但将运营负担转移给了用户。也有实用主义者提出,调用API并自动升级可能是更简单的选择。
构建学习循环需要同时解决三个层面的难题:基础设施层面,需要构建从实时使用中捕获训练数据、进行微调、部署并监控结果的管道;数据治理层面,需要将专有对话和工作流转化为干净、合规、机器可读的训练数据;纪律层面,需要持续评估以确认模型确实在改进结果。企业顾问库马尔·高拉夫(Kumar Gauraw)多次记录了这种模式:团队匆忙进行微调、租用昂贵GPU后,发现一个编写得更好的提示就能在更短时间内解决问题。监管也进一步增加了复杂性。Anthropic的达里奥·阿莫迪(Dario Amodei)最近提议对前沿模型实施类似航空监管的独立审计,在部署前进行独立审计。这对于拥有合规团队的大型企业尚可管理,但对在专有数据上持续微调的中端市场企业则更为困难。
尽管存在上述挑战,纳德拉的核心论点依然值得关注:早期构建专有学习循环的公司能够获得难以复制的优势。这种优势并非源于技术本身,而是因为循环将机构知识编码进一个每次使用都会改进的系统中。这构成了构建资产,而非仅仅购买使用更智能模型的权限。真正的问题在于,企业是否有能力承担构建循环所需的基础设施、治理和纪律,还是应该等待模型本身变得足够强大,从而无需复杂的循环。这是一个关于企业定位的战略选择。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com