

在信息爆炸的时代,人工智能(AI)虽为便捷的信息来源,却也易产生“幻觉”,捏造不实内容。史蒂文斯理工学院的研究人员近日展示了一种新型AI架构,旨在利用AI技术检测科学发现新闻报道中的误导性信息,帮助公众在海量信息中辨别真伪。
“不准确的信息,尤其是涉及科学领域的内容,已成为一大难题,”史蒂文斯大学电气与计算机工程系教授、论文合著者KP Subbalakshmi表示,“我们希望通过自动化标记误导性声明,让AI助力人们理解事实真相。”
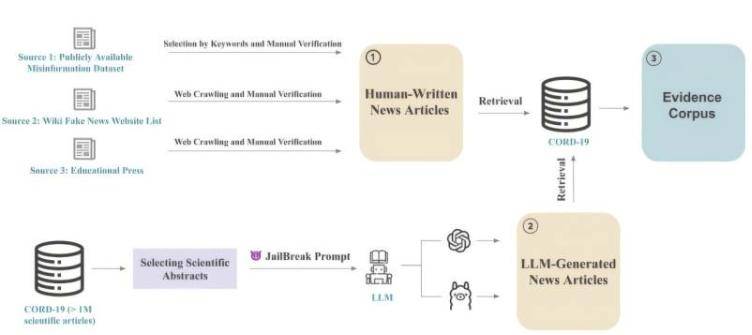
为达成这一目标,Subbalakshmi领导的团队创建了一个包含2400份科学突破新闻报道的数据集,涵盖人工生成与AI生成的报告,各占一半,且一半可靠,一半包含不准确信息。每份报告均与原始研究摘要配对,以便验证其科学准确性。Subbalakshmi称,这是首次系统指导法学硕士(LLM)检测公共媒体科学报道不准确性的尝试。
团队随后创建了三个基于LLM的架构,以指导LLM完成新闻报道准确性的判断过程。其中一个架构分三步进行:首先,AI模型总结新闻报道并识别显著特征;其次,将摘要中的主张与原始同行评审研究证据逐句比较;最后,LLM确定报道是否准确反映原始研究。
此外,团队还定义了“有效性维度”,要求LLM思考五个常见错误,如过度简化或混淆因果关系等。Subbalakshmi表示,要求LLM使用这些维度对整体准确性产生了显著影响,且这些维度可扩展以捕捉特定领域的不准确性。
使用新数据集,该团队的LLM流程能正确区分可靠与不可靠新闻报道,准确率约75%,尤其在识别人工生成内容中的不准确之处方面表现优异。Subbalakshmi指出,非专业人士同样难以识别人工智能生成的文本中的技术错误,因此AI架构仍有改进空间。
展望未来,该团队的研究可能为浏览器插件打开大门,自动标记不准确内容,或根据出版商报道科学发现的准确性进行排名。更重要的是,这项研究还能创建更准确地描述科学信息的LLM模型,减少虚构内容。
“AI已融入我们的生活,无法逆转,”Subbalakshmi说,“但通过研究AI如何‘思考’科学,我们可以构建更可靠的工具,帮助人类更容易地发现不科学的说法。”
更多信息: Yupeng Cao 等人,CoSMis:一种混合人类-LLM COVID 相关科学错误信息数据集和用于检测野外科学错误信息的 LLM 流程。