

近日,麻省理工学院(MIT)的研究人员发现,大型语言模型(LLM)在处理文档或对话时,存在一种“位置偏见”,即模型更倾向于关注开头和结尾的信息,而忽略中间部分。
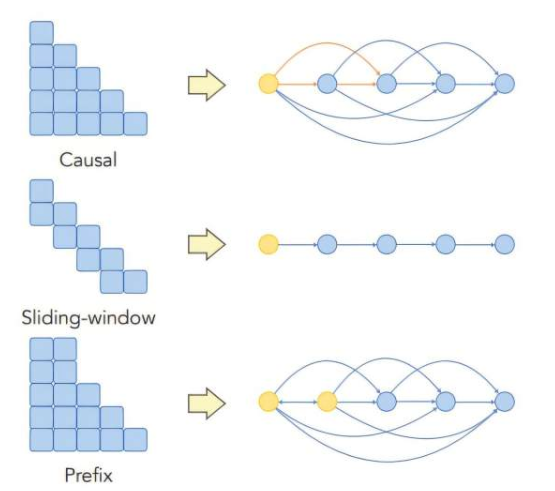
研究人员通过创建理论框架,深入研究了信息在LLM机器学习架构中的流动方式。他们发现,模型架构和训练数据都可能导致位置偏差。特别是那些影响信息在模型内输入词之间传播方式的架构设计,会加剧这一问题。
“这些模型就像黑匣子,用户可能不知道位置偏差会导致模型不一致。”论文第一作者吴欣怡表示。她指出,通过更好地理解模型的底层机制,可以改进这些局限性,从而带来更可靠的聊天机器人、医疗人工智能系统和代码助手。
在实验中,研究人员系统地改变了正确答案在文本序列中的位置,结果显示出一种“迷失在中间”的现象,即检索准确率呈现U形模式。模型在开头和结尾的表现最佳,而在中间部分的表现则有所下降。
为了应对这一问题,研究人员提出了多种策略。他们发现,使用不同的掩蔽技术、从注意力机制中移除额外的层或策略性地采用位置编码,都可以减少位置偏差并提高模型的准确性。
“通过理论与实验相结合,我们能够洞察模型设计选择所带来的后果。”阿里·贾德巴伊教授表示。他强调,在高风险应用中使用模型时,必须了解其何时有效、何时无效以及原因。
未来,研究人员希望进一步探索位置编码的影响,并研究如何在某些应用中策略性地利用位置偏差。这一研究不仅为Transformer模型核心的注意力机制提供了理论视角,还为改进模型性能和可靠性提供了重要参考。
更多信息: Xinyi Wu 等,《论 Transformer 中位置偏差的出现》,arXiv (2025)。期刊信息: arXiv