

斯坦福大学研究人员开发出一款创新的计算机视觉模型,能够识别物体各部分在现实世界中的功能,推动自主机器人工具选择与使用效率的提升。在人工智能领域,传统计算机视觉模型已实现二维图像物体识别,但理解物体各部分功能仍是待解难题。斯坦福大学此次推出的新模型,不仅能识别物体各部分,还能辨别其现实用途,并在物体间以像素为单位进行功能映射。
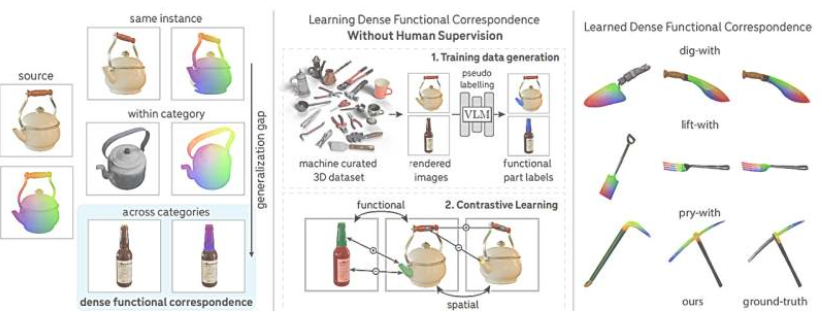
该模型的核心在于实现“功能对应”,即跨物体类别识别并映射具有相同功能的像素区域。例如,模型能识别玻璃瓶与茶壶的壶嘴,并理解其倒水功能。共同第一作者斯蒂芬·斯托贾诺夫解释:“我们希望构建一个支持泛化的视觉系统,实现技能从一个物体到另一个物体的迁移。”这一突破使机器人能区分切肉刀与面包刀,或泥铲与铲子,并选择合适工具完成任务。
传统方法依赖人工标注实现稀疏功能对应,而新模型采用弱监督方案,利用视觉语言模型生成标签,仅需人类专家控制数据质量。这种方法更高效经济,赵(Linan “Frank” Zhao)表示:“几年前需大量人力完成的任务,现在可用更少资源实现。”例如,水壶与瓶子的例子中,模型能精确对齐壶嘴与瓶口像素,实现密集功能映射。
目前,该系统已在图像测试中验证有效性,虽未在现实机器人实验中测试,但团队相信其将为机器人技术与计算机视觉带来巨大进步。密集功能对应标志着人工智能从模式识别转向物体推理,新系统能推断意图而不仅是识别像素。
更多信息: 弱监督密集函数对应学习。期刊信息: arXiv