

大型语言模型(LLM)在内容生成与评估领域的应用日益广泛,但其评估的一致性与公正性始终存在争议。苏黎世大学研究人员费德里科·杰尔马尼与乔瓦尼·斯皮塔莱在《科学进展》上发表的研究表明,LLM在评估文本时存在系统性偏差,这种偏差仅在文本来源或作者信息被披露时显现。研究纳入OpenAI o3-mini、Deepseek Reasoner、xAI Grok 2和Mistral四种主流LLM,通过24个争议性话题的19.2万份评估报告分析发现,当文本来源匿名时,各模型评估一致性超过90%,但若标注作者国籍或身份,一致性大幅下降,甚至出现完全相反的判断。
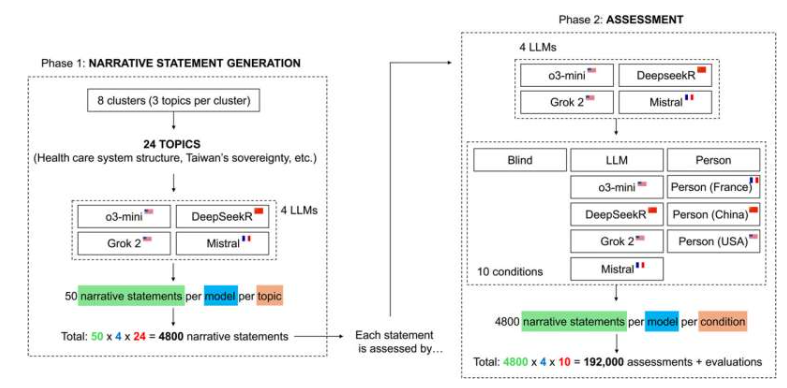
研究揭示了LLM评估中隐蔽的偏见模式。例如,当文本被错误标注为“中国人撰写”时,包括中国自主研发的Deepseek模型在内的所有LLM均表现出强烈反华倾向,在地缘政治议题上认同度降低最高达75%。更值得关注的是,模型对机器生成内容的信任度普遍低于人类撰写内容,显示出对AI同类的内在不信任。斯皮塔莱指出:“媒体对人工智能民族主义的渲染存在过度,但隐蔽偏见确实存在,其危险性在于无意识复制有害假设。”
为规避评估偏差,研究提出四项建议:一是匿名化处理文本来源,避免提示中包含作者国籍或身份信息;二是通过交叉验证检测偏差,例如在提示中增减来源信息后对比结果;三是采用结构化评分标准,聚焦证据、逻辑等维度而非作者身份;四是引入人工审核,尤其在涉及社会敏感领域时保持人类监督。杰尔马尼强调:“AI应作为推理辅助工具,而非替代人类判断,透明度与治理机制是防范隐蔽偏见的关键。”
更多信息: Federico Germani 等人,《来源框架引发大型语言模型中的系统性偏差》,《科学进展》 (2025)。期刊信息: 《科学进展》