

维度网讯,一组研究人员开发了一种量子神经网络训练框架,可降低训练过程中计算梯度的成本——这是量子机器学习领域长期面临的主要障碍之一。
根据发表在预印本服务器arXiv上的研究,该方法将每个优化步骤所需的电路评估次数从随量子比特数平方级增长减少到仅对数级增长。研究人员表示,这一改进使得在IonQ的Forte Enterprise离子阱量子计算机上能够直接进行基于梯度的训练,并允许他们将这一方法应用于一项临床相关的数据插补任务。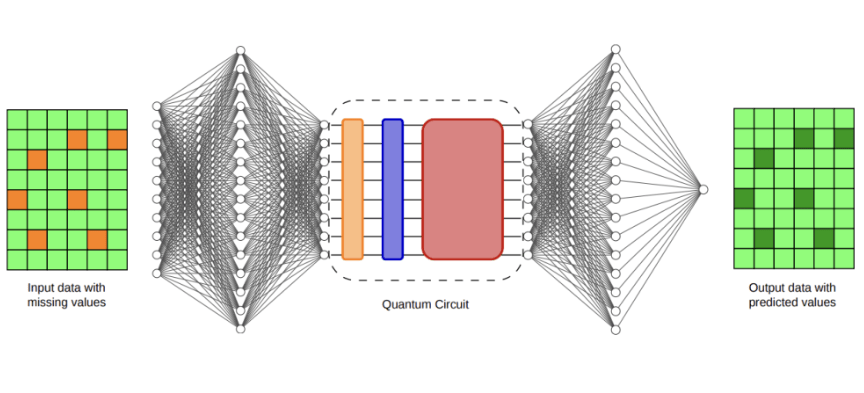
据该团队介绍,这项工作解决了量子机器学习中一个长期存在的挑战。该团队包括来自IonQ、巴黎西岱大学(Université Paris Cité)、法国国家科学研究中心(CNRS)、QC Ware和Quantum Signals的科学家。量子神经网络(QNN)是具有可调参数的量子电路,其训练方式类似于经典神经网络。理论上,它们可能在某些学习任务中提供优势,然而在实际量子硬件上训练它们被证明是困难的,因为计算梯度通常需要重复运行大量量子电路。研究人员报告称,这一开销是许多量子机器学习演示仍局限于模拟或极小规模硬件实验的主要原因之一。
该框架结合了三个协同设计的组成部分,包括专门的电路设计、逐层训练策略和并行梯度计算技术。
传统参数移位方法广泛用于训练量子电路,需要为个别参数进行单独的电路评估。随着模型规模增大,所需评估次数迅速增加。新框架通过三种设计选择来避免这一瓶颈。第一种是名为蝶形网络(Butterfly network)的电路架构,受快速傅里叶变换结构启发,该架构以特定模式排列量子操作,使信息在整个系统中传播,同时保持电路相对较浅。根据研究,该设计随系统规模增大,大幅减少了所需可训练参数的数量。第二种是逐层训练策略,该方法不是同时训练量子神经网络中的每个参数,而是先训练较小的电路块,然后逐步添加新层,优化新层时先前训练的层被冻结。第三种是参数移位规则的并行化版本,由于每个蝶形层内的门作用于不同的量子比特对并且彼此对易,研究人员可使用恒定数量的电路执行来计算整个层的梯度,而非单独评估每个参数。这些技术共同大幅减少了训练过程中所需的量子电路评估次数。研究人员通过实例报告了扩展优势:对128量子比特的蝶形电路应用传统参数移位方法需要1792次电路评估来计算梯度,而他们的方法只需要28次。
为评估该框架,研究人员选择了临床数据插补,这是一个超出传统量子计算基准的问题。数据插补涉及填补数据集中的缺失条目,在医疗记录中由于测量时间表不一致、传感器故障或数据收集不完整,缺失信息很常见,准确的插补可显著影响医疗分析中使用的下游预测模型。团队使用了MIMIC-III数据集,这是一个被广泛研究的去标识化重症监护病房记录集合,他们在数据集中引入缺失值,然后比较了各种重构缺失信息的方法。基准包括常见的统计技术如均值插补和零填充,以及更复杂的方法如K近邻插补、链式方程多重插补(MICE)、MissForest和基于神经网络的Deep MICE模型。研究人员通过预测患者生存率间接评估插补质量,并使用受试者工作特征曲线下面积(AUC)进行衡量。在经典方法中,Deep MICE产生了最强的平均性能,AUC达到0.7176。在16量子比特上训练的混合量子-经典模型实现了0.7147的AUC,而32量子比特混合模型实现了0.7132的AUC,两者与领先的经典结果相差不到千分之几。尽管量子模型未超越最佳经典基线,但它们性能范围窄,且多次运行中变异性较低。研究人员表示,这种稳定性可能表明由结构化蝶形架构和训练协议带来的有益归纳偏置。
该研究提供了在商用量子计算机上直接训练的重要演示。研究人员在IonQ的Forte Enterprise离子阱系统上训练了一个16量子比特蝶形量子神经网络的最后一层,模型的早期阶段在模拟中训练,然后整合到硬件训练的网络中。他们比较了三种场景,包括理想模拟、含噪声模拟和直接硬件执行。根据结果,三种训练方法之间的性能差异在统计上不显著,硬件训练模型获得了与模拟模型相当的结果,同时保持了相似的预测性能。研究人员报告称,这证明了对数缩放训练框架足够稳健,能够在当前硬件噪声水平下运行。这一发现很重要,因为许多先前量子机器学习演示严重依赖模拟而非实际量子处理器,硬件噪声和长训练时间常常使直接优化不切实际。IonQ使用的离子阱架构可能有所帮助,该系统提供全连接量子比特连接,使得蝶形电路能够在没有大量编译开销的情况下实现。
研究还探索了更大的系统规模。由于直接32量子比特训练仍然计算密集,研究人员使用矩阵乘积态张量网络模拟来训练更大的量子层,推理则在IonQ硬件上执行。由此产生的32量子比特混合模型的性能与具有等效隐藏层宽度的经典神经网络相当。研究人员将此解释为证据,表明通过逐层框架产生的更大量子电路仍与真实硬件兼容,并且可以在没有可测量退化的情况下运行。
该工作包括几个重要的局限性。研究聚焦于一个受控的概念验证插补任务,而非生产规模的医疗工作流程,仅有一个特征列使用量子模型进行插补,其余缺失值由经典方法处理。缺失数据模式也是使用完全随机缺失模型生成的,而真实世界的临床数据通常表现出更复杂的缺失模式。最后,混合模型匹配而非超越了最强经典基线,结果展示了可行性和竞争力,而非明确的量子优势。研究人员还指出,在潜在性能优势变得明显之前,可能需要更大的系统,基于与经典神经网络架构的比较,他们估计大约需要128量子比特才能匹配研究中使用的最强经典模型的表示能力。即便如此,研究人员认为,该框架的意义不在于当前的性能数字,而在于实现可扩展的硬件上训练。
研究团队包括法国国家科学研究中心(CNRS)和巴黎西岱大学(Université Paris Cité)联合研究实验室——基础信息学研究所(IRIF)的Natansh Mathur,以及法国QC Ware。合著者Panagiotis Kl. Barkoutsos、Masako Yamada和Martin Roetteler隶属于IonQ。研究还包括隶属于IRIF、CNRS、巴黎西岱大学以及Quantum Signals的Iordanis Kerenidis。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com














