
维度网讯,GitHub推出内部人工智能分析代理Qubot,旨在让员工使用自然语言查询数据仓库中的任意数据模型,并在数秒内获得答案。
大型数据与分析组织往往难以实现数据和洞察的自助式访问。GitHub内部有数十个产品团队,为其提供专门的分析支持颇具挑战,因此许多团队需自行解决数据分析问题。尽管存在大量有价值的产品遥测数据可供决策使用,但在没有数据分析师支持的情况下,确定使用的数据模型、粒度、过滤器,并编写查询及验证结果,始终是困难任务。
Qubot作为基于GitHub Copilot的内部分析代理,允许任何Hubber(即GitHub员工)用自然语言提问,例如“哪个用户群体在此功能上留存率最高?”或“上周哪个产品对这一指标的提升贡献最大?”。该工具并非替代报告工具或仪表板,而适用于探索性问题,且维护成本为零,能帮助团队快速熟悉不熟悉的数据集。
Qubot的架构包含三个主要组件:用户界面、上下文层和查询引擎。
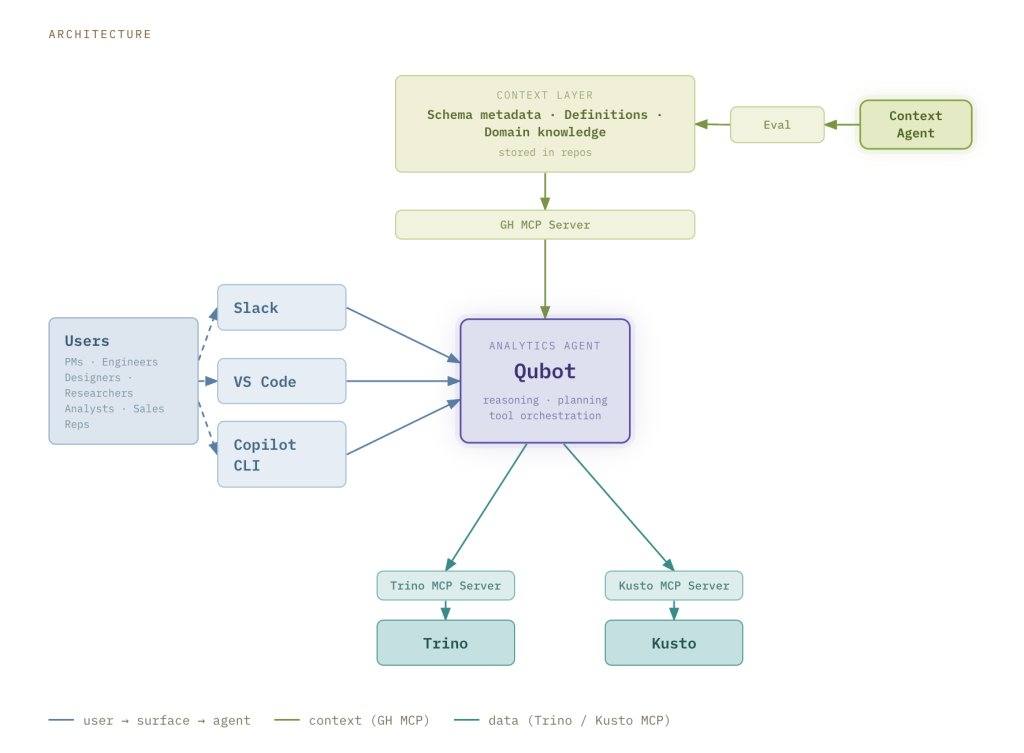
用户界面可通过Slack、VS Code和Copilot CLI访问。Slack界面无需配置,当有人在Qubot Slack频道中提问时,系统会生成一个Qubot实例,答案直接显示在Slack中,用户可分享结果并迭代细化问题。结果还以Markdown报告形式存储在拉取请求中。Qubot在VS Code和Copilot CLI中作为插件安装后即可使用。
上下文层以联邦方式构建,知识针对数据类型定制。对于原始事件(青铜层)数据,拥有产品团队贡献的遥测上下文;对于符合事实和维度(银层)数据,拥有数据与分析团队维护的查询示例和使用指南;对于为特定业务用例策划的金层数据,拥有业务规则和指标定义。ETL管道通过额外信号和派生元数据丰富上下文层,运行时通过GitHub MCP服务器加载。
上下文代理简化了联邦式上下文贡献。团队可通过标准化模板或引用仓库贡献上下文,代理会将信息摄取、组织并规范化为结构化格式。上下文层或代理配置的每次更改在发布前会通过评估框架衡量,该框架包含精心设计的测试用例、自动运行编排和统计聚合组件,用于衡量响应准确性、延迟并捕获回归问题。
查询引擎通过MCP服务器连接到Kusto和Trino。Kusto速度快,适合对近期事件数据进行探索性查询;Trino处理复杂连接和更深入历史分析。Qubot默认使用Kusto,并在需要时自动切换到Trino。
Qubot在GitHub已得到广泛应用,数百名用户执行了数千次查询。数据与分析频道中的问题数量大幅减少,员工可更自主地探索数据。上下文层成为增强Copilot推理能力的关键,结构良好的上下文不仅让Qubot更准确,还能将返回正确答案的速度提升三倍。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com









