

当我们观察周围世界时,大脑不仅能识别具体物体,还能理解场景的广泛含义。然而,长期以来,科学家们一直缺乏有效手段来量化这种复杂理解。今日发表在《自然机器智能》杂志上的一项新研究,由蒙特利尔大学心理学副教授伊恩·查雷斯特携手明尼苏达大学、德国奥斯纳布吕克大学及柏林自由大学的同事,通过大型语言模型(LLM)成功解决了这一难题。
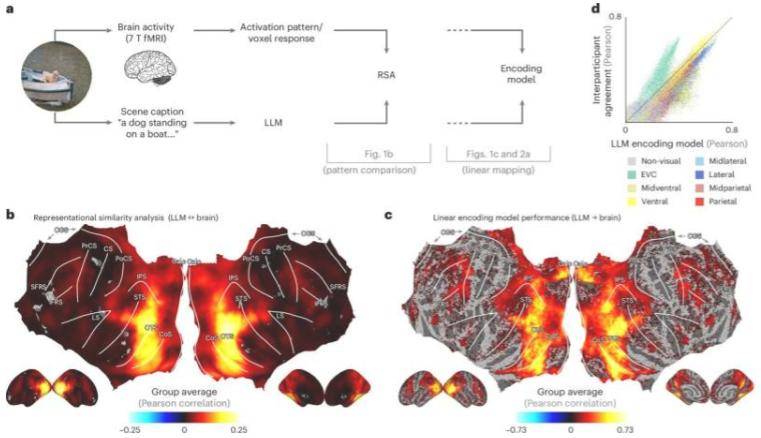
“我们将自然场景描述输入LLM,创建了基于语言的指纹来表征场景含义,”查雷斯特解释道,“这些指纹与人们在观察相同场景时的核磁共振扫描记录的大脑活动模式高度吻合,无论是玩耍的孩子还是城市天际线。”他进一步说明,借助LLM,研究人员能用一句话解码人们感知到的视觉场景,还能预测大脑对食物、地点或人脸场景的反应。研究团队更进一步,训练人工神经网络接收图像并预测LLM指纹,发现其匹配大脑反应的能力超越了许多现有最先进的AI视觉模型。
尽管这些模型基于较少数据训练,但结果依然显著。奥斯纳布吕克大学机器学习教授Tim Kietzmann及其团队为人工神经网络构想提供了支持,柏林自由大学Adrien Doerig教授为该研究第一作者。“我们的发现表明,人类大脑处理复杂视觉场景的方式可能与现代语言模型理解文本的方式惊人相似,”查雷斯特表示。这项研究为解码思维、优化脑机接口及构建更智能的AI系统开辟了新路径,使其能更接近人类“看”世界的方式。未来,更先进的视觉计算模型有望助力自动驾驶汽车做出更明智决策,甚至可能为视力受损人群开发视觉假体。
更多信息: Adrien Doerig 等人,《人脑中的高级视觉表征与大型语言模型相一致》,《自然机器智能》 (2025)。期刊信息: 《自然机器智能》