

在使用大型语言模型(LLM)时,实现低延迟的高质量输出是关键需求,尤其在聊天机器人、AI代码助手等现实应用场景中。当前,LLM多采用自回归解码框架,但此方法效率较低,生成长序列响应时耗时线性增长。为提升效率,研究人员正探索“猜测和验证”框架的推测解码,即利用小型LLM预先猜测文本标记,再由原始LLM验证,以缩短响应时间。然而,这些方法常需额外训练和大量计算资源,且加速效果有限。
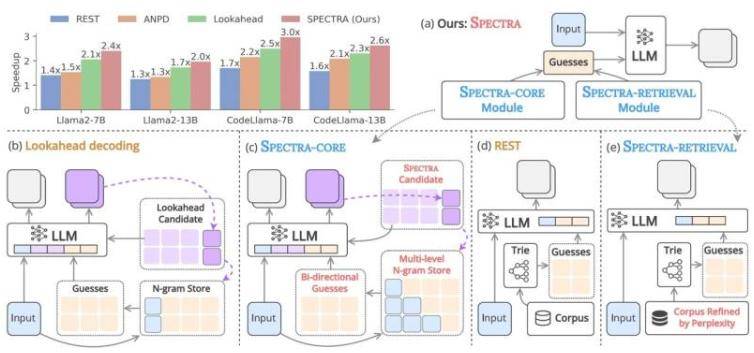
针对此问题,日本先端科学技术大学院大学(JAIST)的Nguyen Le Minh教授及其团队开发了名为SPECTRA的新型推测解码框架。该框架无需额外训练即可加速文本生成。“SPECTRA由两个核心组件构成:SPECTRA-CORE,它可无缝集成到LLM中;以及SPECTRA-RETRIEVAL,它进一步提升性能。”Nguyen教授介绍道。SPECTRA-CORE利用LLM预测的文本分布模式生成高质量猜测,通过双向搜索N-gram词典快速准确预测不同长度短语,并持续更新词典以优化性能。
为进一步加快速度,SPECTRA-RETRIEVAL模块被集成到系统中。与现有方法不同,它筛选文本数据集,仅保留目标LLM易于预测的部分,确保高质量、相关数据用于模型训练或微调,实现与SPECTRA-CORE无缝集成。在Llama 2、Llama 3和CodeLlama三个LLM系列上的测试显示,SPECTRA实现了4倍加速提升,超越了REST、ANPD和Lookahead等非训练推测解码方法。Nguyen教授表示:“通过集成即插即用的SPECTRA-CORE模块与改进的SPECTRA-RETRIEVAL模块,我们能在不同任务和模型架构中实现大幅加速,同时保留原始模型输出质量。”
更多信息: Nguyen-Khang Le 等人,SPECTRA:通过优化内部和外部推测实现更快的大型语言模型推理,第 63 届计算语言学协会年会论文集(第 1 卷:长篇论文)(2025 年)。