

6月5日,腾讯混元宣布提出Stem稀疏注意力算法,相关成果已被机器学习顶会ICML-26收录。该算法面向大模型长上下文推理中的预填充瓶颈,通过Token位置衰减和输出感知度量两项设计,在仅使用25%计算预算的情况下逼近稠密注意力精度,并在128K上下文场景下将首字延迟降低3.6倍。
Stem的科研价值集中在一个长期困扰大模型部署的问题上:输入越长,自注意力计算成本越高,模型吐出第一个字之前的等待时间越长。长文档问答、代码库分析、合同审查、知识库检索、多轮对话记忆和企业智能体编排,都会把上下文长度推到数万甚至十万级别;在这种场景中,模型生成后续文字的速度固然重要,但用户首先感受到的是“首字延迟”,也就是系统读完整段长输入、完成预填充计算并开始输出第一个token所需的时间。传统Transformer自注意力需要让token之间进行大范围交互,序列长度增长后计算量会迅速放大,稀疏注意力因此成为降低长上下文成本的重要方向。Stem的关键贡献在于,它没有简单地把注意力计算均匀削减,而是从因果信息流重新理解token在模型内部的作用。在因果注意力结构中,靠前位置的token会不断参与后续token的信息聚合,像“树干”一样支撑后续信息传递。如果稀疏算法对所有位置采用相同预算,容易忽视早期token在长序列中的递归依赖作用。Stem提出的Token位置衰减策略,就是在不增加总预算的前提下,对不同位置重新分配计算资源,把更多注意力预算留给信息流中更关键的位置,从而减少因过度稀疏造成的精度损失。另一项输出感知度量则解决“选哪些token更有价值”的问题。以往方法更多依赖注意力分数判断重要性,但注意力分数高并不必然代表最终输出贡献大,Value向量携带的信息幅度同样会影响结果。Stem把路由概率和输出信号贡献结合起来衡量token价值,使稀疏选择更贴近模型实际输出过程。这种设计让稀疏注意力从单纯减少计算,转向围绕信息流和输出贡献进行选择,为长上下文推理提供了更细粒度的算法路径。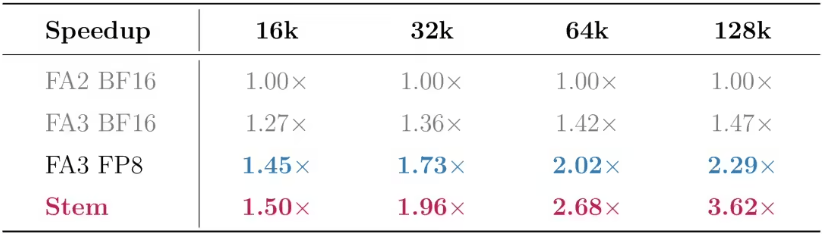
真正影响产业落地的,是算法收益能否转化为硬件上的可测加速。
腾讯混元这次同步给出的全栈方案,把Stem算法与HPC算子库结合起来,解决了稀疏注意力从理论到部署之间的关键断点。很多稀疏算法在论文实验中能够减少计算量,但进入GPU推理系统后,可能因为选块、索引、跳块、数据搬运和缓存访问带来额外开销,最终端到端速度提升低于理论预期。Stem配套的HPC-Stem和HPC-BSA算子围绕这一问题做了工程优化:前者加速评估选块流程,后者面向块级稀疏注意力执行过程,使被跳过的计算块能够在GPU上真正减少开销。尤其在Hopper架构、FP8量化、Paged KV Cache和vLLM推理框架等生产环境因素叠加后,稀疏收益是否能够稳定兑现,直接决定算法有没有实际应用价值。腾讯混元将Stem集成进Hy3 preview的W8A8-FP8量化推理场景,并在128K上下文下实现首字延迟降低3.6倍,说明该方案已经越过单纯学术验证阶段,开始面向工业级推理链路进行优化。对企业级大模型应用而言,这类改进的意义非常直接:同样一段超长输入,系统更快完成预填充,就能显著改善用户等待体验;同样一组GPU资源,长上下文请求处理效率提升,也会降低服务成本,提高平台承载更多复杂任务的能力。随着模型上下文窗口继续扩展,企业不再只是追求模型“能读多长”,还要追求“读得快、成本低、精度稳”。Stem把算法层面的信息选择和算子层面的硬件执行打通,使长文本推理优化从模型结构研究延伸到计算系统协同,这也是其被视为科创成果的重要原因。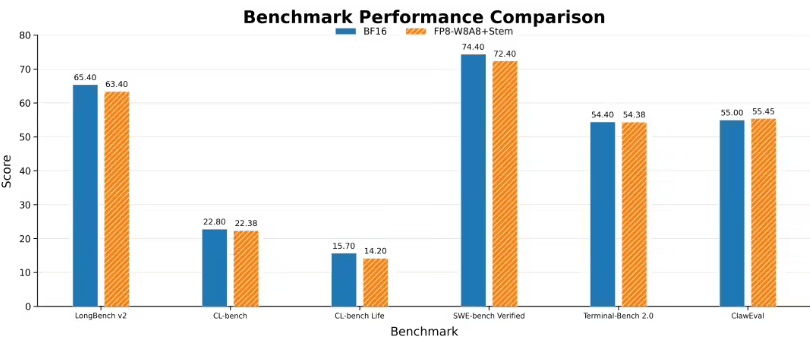
这项成果还提示大模型竞争正在进入更深的基础设施层。过去模型能力提升更多体现在参数规模、训练数据、指令微调和应用生态上;长上下文成为主流能力后,预填充、KV缓存、稀疏注意力、量化推理、算子优化和调度系统开始决定模型能否低成本运行。Stem的出现说明,国产大模型团队正在把研发重点延伸到算法、算子和推理框架协同优化,而不是只在模型参数和榜单分数上竞争。对于金融、政务、工业、医疗、法律和科研等需要处理长文档的行业应用,首字延迟下降会直接影响系统可用性:合同审阅不必长时间等待,知识库问答可以处理更长上下文,智能体可以在更大任务链中保留更多历史信息,研发助手也能一次性读取更多代码和文档。后续如果Stem算法与开源算子继续扩展到更多模型、更多硬件架构和更长上下文窗口,其价值将不局限于腾讯混元体系,也可能成为长文本高效推理领域的一类通用方法参考。
从技术路线看,Stem的突破并不是简单追求“少算一点”,而是在尽量少损失精度的前提下,把大模型长上下文推理中最昂贵的注意力计算压缩到更可部署的范围。随着百万级上下文、企业智能体和复杂多模态任务继续发展,首字延迟会成为衡量大模型工程能力的重要指标。腾讯混元这项成果为长上下文推理提供了新的优化思路,也让稀疏注意力从算法论文进一步走向真实硬件加速和生产环境验证。