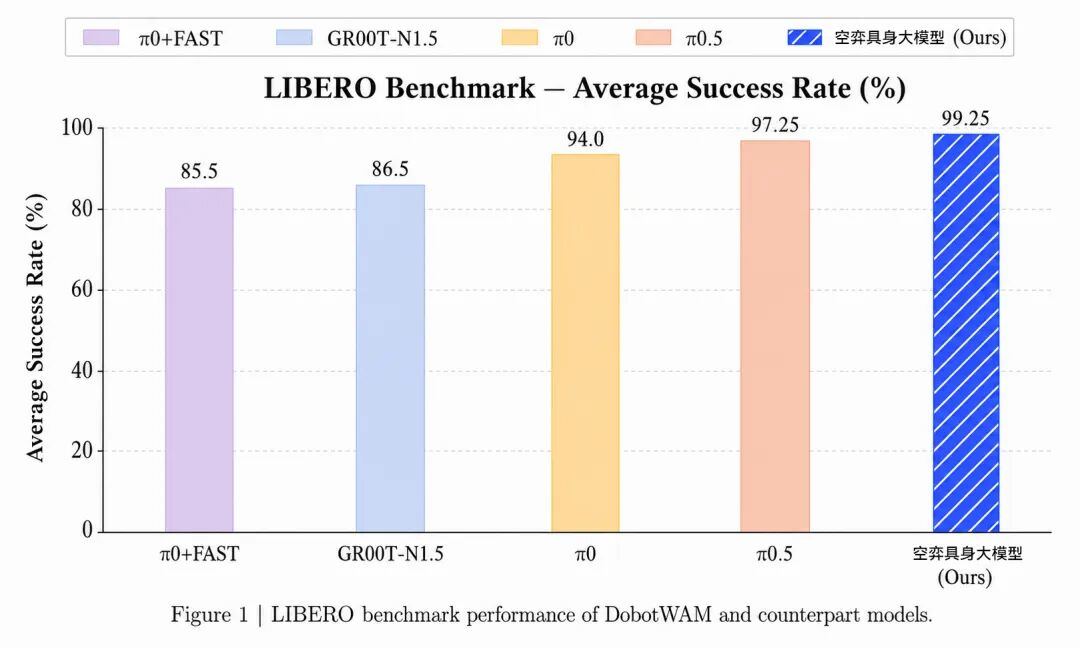
维度网讯,中国越疆正式发布自研世界动作模型“空弈DobotWAM”。在具身智能标准评测基准LIBERO上,该模型完成了LIBERO-Spatial、LIBERO-Object、LIBERO-Goal和LIBERO-10四个标准任务套件,覆盖空间关系理解、物体泛化、目标指令理解以及长时序任务执行等关键能力维度,平均成功率达到99.25%,领先于π0.5、π0、GR00T-N1.5、π0+FAST等公开模型以及行业内已有数据公布的其他模型结果。
其中,空弈DobotWAM在LIBERO-Object上实现100/100全部成功,在Spatial、Goal和LIBERO-10三个套件中均达到99/100。
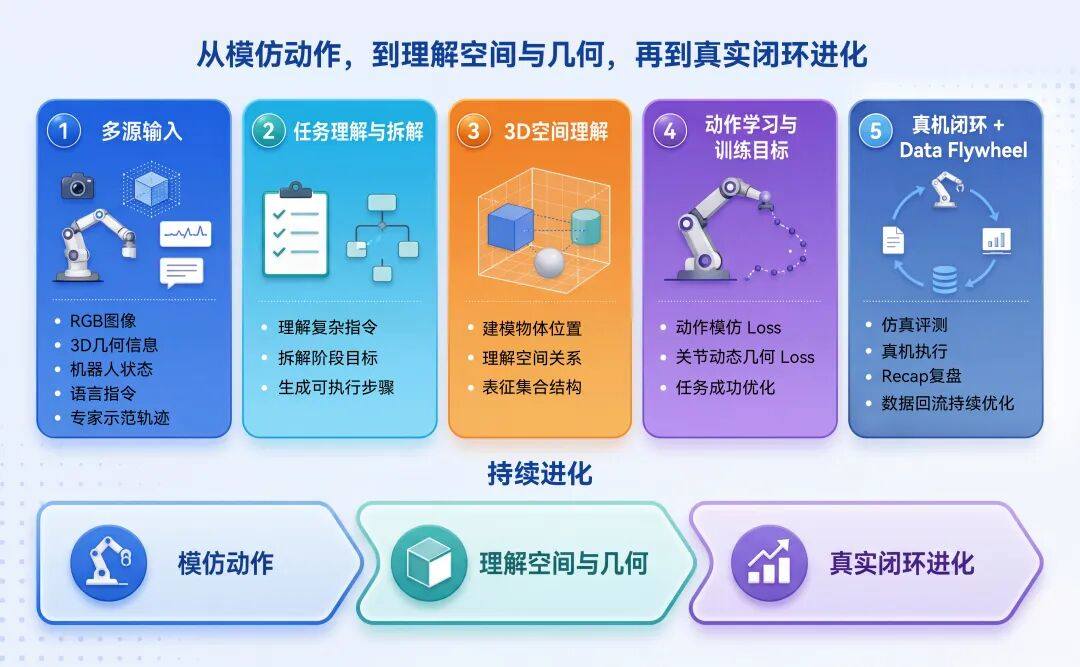
越疆空弈DobotWAM具身大模型在感知、理解、控制和数据闭环上进行了系统性设计。通过3D信息增强场景理解,通过关节动态几何loss提升动作稳定性,通过高级VLM backbone拆解复杂任务,并通过真机Recap实验与高质量数据飞轮持续回流真实操作经验,融合到统一的世界动作模型框架中,使模型能够更稳定地完成多物体、多阶段、长时序机器人操作任务。
机器人走向真实应用,需要面对的不是静态、规则、完全可控的环境,而是充满变化的开放场景。同一个任务中,物体位置、指令表达、机器人初始姿态以及物体尺寸、形状、材质和摆放方式都可能不同。机器人的真正挑战在于理解物体之间的空间关系、判断任务目标、生成符合机械臂运动结构的动作,并在多步骤执行中保持全局目标一致。近年来,VLA模型成为具身智能动作生成的重要范式,它将视觉观测、语言指令和机器人动作统一建模,在数据覆盖充分、任务边界清晰的场景中展现出较高执行效率。但如果模型过度依赖二维图像模式或离线轨迹模仿,在面对空间扰动、物体变化、长流程任务和真实接触反馈时,仍容易出现动作漂移、目标丢失,或局部动作正确但整体任务失败的问题。
越疆空弈DobotWAM具身大模型的思路,是在视觉-语言-动作建模基础上,进一步引入三维空间理解、机器人运动几何约束和真实数据闭环机制,让模型在模仿动作之外,学会理解动作的逻辑。
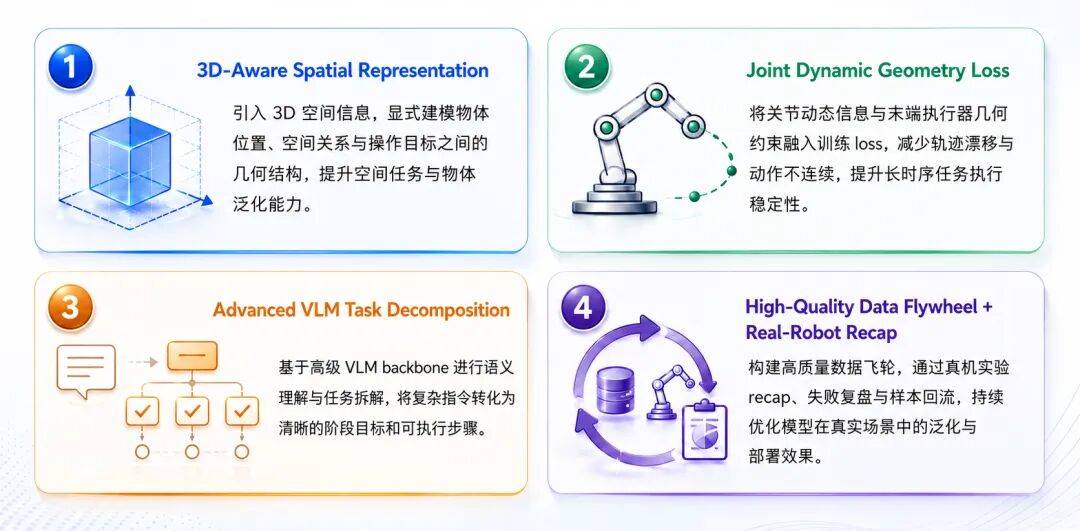
该模型的高成功率源于四项关键技术突破。3D-Aware Spatial Representation将3D空间信息引入视觉-语言-动作建模,使模型显式感知物体位置、空间关系与操作目标之间的几何结构。Joint Dynamic Geometry Loss将机器人关节动态信息与末端执行器几何约束融入训练loss,减少轨迹漂移和抓取失败,提升长时序任务执行稳定性。Advanced VLM Task Decomposition基于高级VLM backbone对复杂语言指令进行语义理解与任务拆解,将长流程操作分解为清晰的阶段目标。High-Quality Data Flywheel + Real-Robot Recap构建高质量数据飞轮,以Recap真机实验为核心,持续吸收成功、失败及长尾场景的真实经验。
为了验证模型在真实物理环境中的执行能力,选取了分类任务抓取、插充电器和插笔帽三类精细操作任务,验证小目标定位与姿态估计、强几何约束下的末端控制以及接触过程中的稳定执行与误差修正能力。

在LIBERO标准评测中,空弈DobotWAM具身大模型以99.25%平均成功率展现出高水平的语言条件机器人操作能力。在真实机器人演示中,该模型完成了分类抓取、插充电器、双臂协作旋转和插笔帽等精细操作任务,验证了其在真实物理环境中的空间理解、姿态控制和接触执行能力。越疆将继续围绕真实机器人场景推进空弈DobotWAM具身大模型的模型迭代。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com