维度网讯,谷歌近日发表技术博文,阐述AI崛起对其网络架构的重塑。博文指出,随着Gemini、Veo、搜索及Cloud AI等服务的底层基础设施日益依赖为大规模东西向流量、低延迟和高弹性设计的紧密集成网络系统,网络已成为AI系统本身的基础层。Amin Vahdat在博文中详细描述了这一转变。
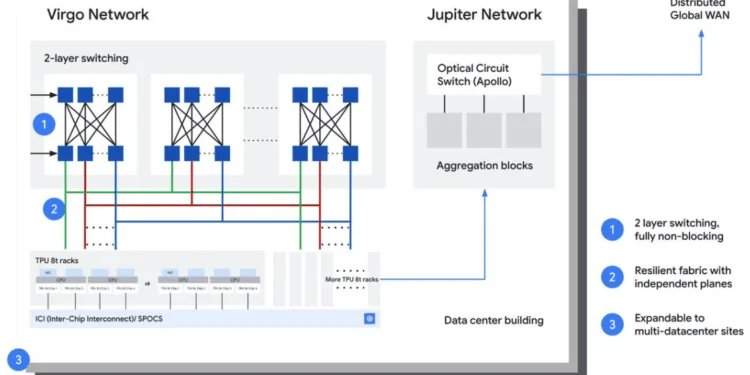
谷歌目前将AI基础设施视为一个前所未有的分布式计算平台。训练和推理工作负载正跨越多个集群、建筑乃至园区,要求通过互连结构在可预测延迟下传输海量数据。谷歌描述了一种可跨地点整合资源的架构,形成其所谓的大规模AI“超算机”。这需要集群网络、区域光传输和全球广域网之间的紧密协调。谷歌私有骨干网已覆盖超过775万公里的陆地和海底电缆系统,通达200多个国家和地区,以支撑全球分布式AI工作负载。
博文指出,AI正模糊数据中心网络与广域网络之间的传统边界。历史上,数据中心结构针对建筑内的短程东西向流量优化,而广域网负责区域间的长途连接。如今,大模型训练会在数千个加速器之间产生同步流量,往往超出单个POD或园区,这使得带宽扩展、拥塞管理、光容量规划和流量工程必须作为一个统一系统运作。谷歌将此视为交换、路由、光传输和软件定义控制之间的架构融合。
软件在编排这些网络中发挥着关键作用。谷歌指出,AI工作负载的放置日益依赖于跨多层基础设施的智能流量管理。软件定义网络用于平衡流量、隔离故障、优化延迟,并在竞争工作负载之间动态分配容量。这对于大规模分布式训练尤为重要,因为同步集群中最慢的链路可能影响整体模型性能。谷歌的网络控制平面正日益充当计算与传输之间的编排层。
博文还强调了硬件创新在AI网络中的重要性。谷歌提及对定制网络芯片、硬件加速和直接内存访问技术的投入,以最小化延迟并提升计算资源间的吞吐量。这与超大规模云提供商向基于RDMA的网络、光规模扩展结构以及专为AI集群设计的高基数交换架构的趋势相符。博文内容停留在系统层面,未涉及具体产品细节,但反映了网络正与加速器、内存系统和存储协同设计的行业转变。
谷歌的架构与其更广泛的AI超算机计划紧密一致,包括在Cloud Next上推出的Virgo扩展结构。该平台大规模连接TPU和GPU资源,并允许工作负载跨数据中心边界分布。类似的方法也出现在行业中,包括英伟达的NVLink和基于InfiniBand的AI结构、Meta的大规模AI集群网络、微软的Azure AI骨干网,以及AWS在EFA和定制光网络方面的工作。谷歌的贡献展示了这些概念如何从集群延伸到城域和全球基础设施。
博文关键信息包括:谷歌将网络定位为AI系统的核心架构组件,而非支撑性传输层;AI工作负载日益跨多个集群和园区运行,需要极高容量的互连;随着东西向AI流量的地理范围扩大,数据中心结构与广域网架构之间的传统分隔正在缩小;谷歌依赖软件定义的流量工程来优化跨网络层的性能和工作负载放置;网络弹性仍是核心,在数据中心、区域和骨干基础设施中内置了路由多样性和故障隔离;该公司持续投入定制网络硬件和高性能传输以支持低延迟AI通信;谷歌的架构既支持内部AI工作负载,也支持使用公司AI超算机基础设施的外部Google Cloud客户。
“AI工作负载正在改变网络每一层的基础设施需求的规模和形态,”谷歌工程团队写道,并描绘了一个数据中心网络与全球骨干基础设施日益作为一个单一分布式系统运行的环境。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com