

维度网讯,Artificial Analysis 推出了业界首个自主 AI 基准测试 AgentPerf,为开发者、企业和基础设施提供商提供了比较自主 AI 系统的标准方法。首轮测试结果显示,NVIDIA Blackwell Ultra NVL72 平台在自主 AI 工作负载中展现了领先性能,每兆瓦支持的智能体数量达到 NVIDIA Hopper 系统的 20 倍。

自主 AI 的工作负载与对话式 AI 有着本质区别。一次聊天完成如同短跑,只需一次大语言模型(LLM)调用和一次回应。而智能体则更像接力赛,它将目标分解为多个步骤,持续进行直到任务完成。
这种模式会导致数十到数百次 LLM 调用串联在一起,每次调用都将不断增长的上下文传递给下一次,并在每次交接时进行代码编译与执行、数据库搜索和网页浏览等工具调用。其复杂性不是相加,而是相乘。
这种区别对性能衡量至关重要。现有的 AI 推理基准测量的是单次 LLM 调用,即 LLM 对单个请求的响应速度以及系统能同时处理多少请求。它们并非为自主工作负载而设计,因为链式 LLM 调用、工具调用延迟和不断增长的上下文对加速计算系统的压力与单次 LLM 调用截然不同。
对于大规模构建和部署智能体的公司而言,了解智能体的响应速度、可同时部署的数量以及 AI 基础设施每投入一美元和每瓦电能所能完成的有用工作,至关重要。
在首轮测试中,AgentPerf 使用 DeepSeek V4 Pro(一种大型混合专家模型,代表了当前驱动最强智能体的前沿模型类别)来衡量自主性能。在该工作负载下,NVIDIA GB300 NVL72 在基准测试中取得了最高性能,每兆瓦支持的智能体数量是 NVIDIA HGX H200 系统的 20 倍。
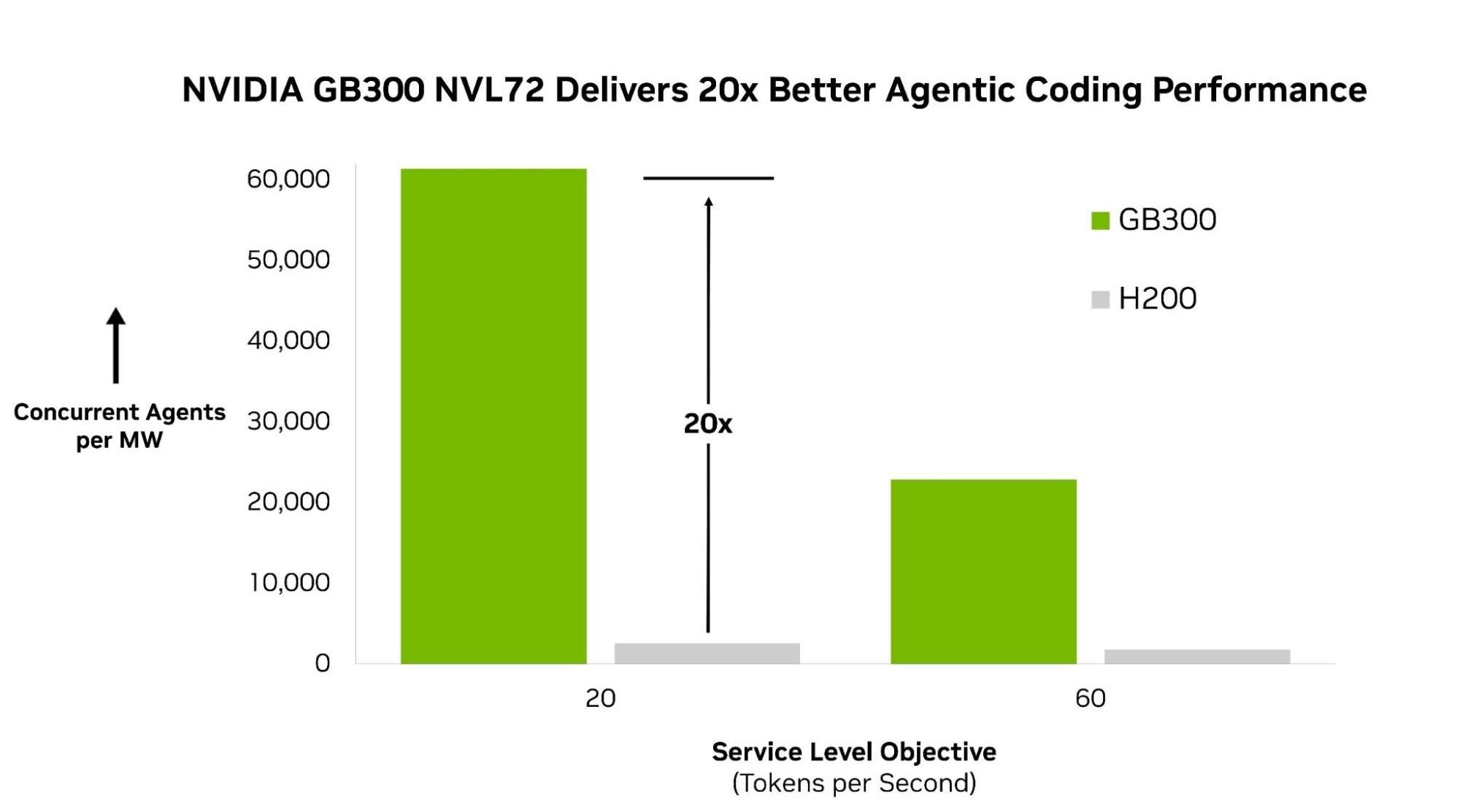
这一性能优势源于全栈的极致协同设计。GB300 NVL72 将 72 块 GPU 连接成一个机架级系统,使得 DeepSeek V4 Pro 等大型 MoE 模型能够高效地大规模分布执行。CUDA 内核通过重叠通信与计算进一步加速,因此跨专家协调的成本被吸收而非增加延迟。随着并发智能体会话的规模扩大,NVIDIA TensorRT LLM 保持了效率,它将输入处理与输出生成分离,从而可以独立优化每个环节。这些结果基于从头构建的基准测试方法,旨在反映自主 AI 在生产中的实际运行方式。
AgentPerf 基于真实的编码智能体轨迹构建。智能体接收任务、读取文件、编写和编辑代码、执行命令并根据结果迭代,所有数据均来自 12 种以上编程语言的真实公共代码仓库。长序列长度、工具调用模式和延迟均代表了真实世界的编码工作流。AgentPerf 衡量平台在满足响应性和输出令牌率等既定性能阈值的同时,能同时支持多少此类自主任务。工具调用并未实际执行,而是使用代表性的 CPU 处理时间进行模拟,因此结果的差异仅反映加速计算性能的影响。结果可直接转化为基础设施决策:每个加速器和每兆瓦电能可运行多少并发自主任务。
领先的推理提供商,包括 Baseten、DeepInfra 和 Together AI,已在 NVIDIA Blackwell 上为前沿模型(如 DeepSeek V4 Pro)上的自主工作负载提供服务。Together AI 在 NVIDIA Blackwell 上为 Cursor(一个 AI 驱动的自主编码平台)提供实时推理。Cursor 的智能体在开发者继续工作时调试问题、生成功能并执行重构。DeepInfra 为 Pam.ai 提供支持,这是一个面向汽车经销商的 AI 劳动力平台,它完全在 NVIDIA Blackwell 上部署智能体来预订服务预约、处理电话和进行外呼销售活动。随着 NVIDIA 和开源生态系统持续优化推理软件,自主工作负载的性能和效率将不断提升。NVIDIA Vera Rubin 架构现已全面投产,将带来下一代基础设施容量,以满足不断增长的规模化自主 AI 需求。更多关于 AgentPerf 方法论及全栈优化的细节,可参阅相关技术博客。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com














