
维度网讯,新浪微博一支九人研究团队推出了VibeThinker-3B,这是一个参数量为30亿的紧凑型语言模型,在多项推理基准测试中,其成绩匹配或超越了来自谷歌DeepMind(Google DeepMind)、开放人工智能(OpenAI)、人工智能安全公司Anthropic和深度求索(DeepSeek)等机构的更大规模系统。
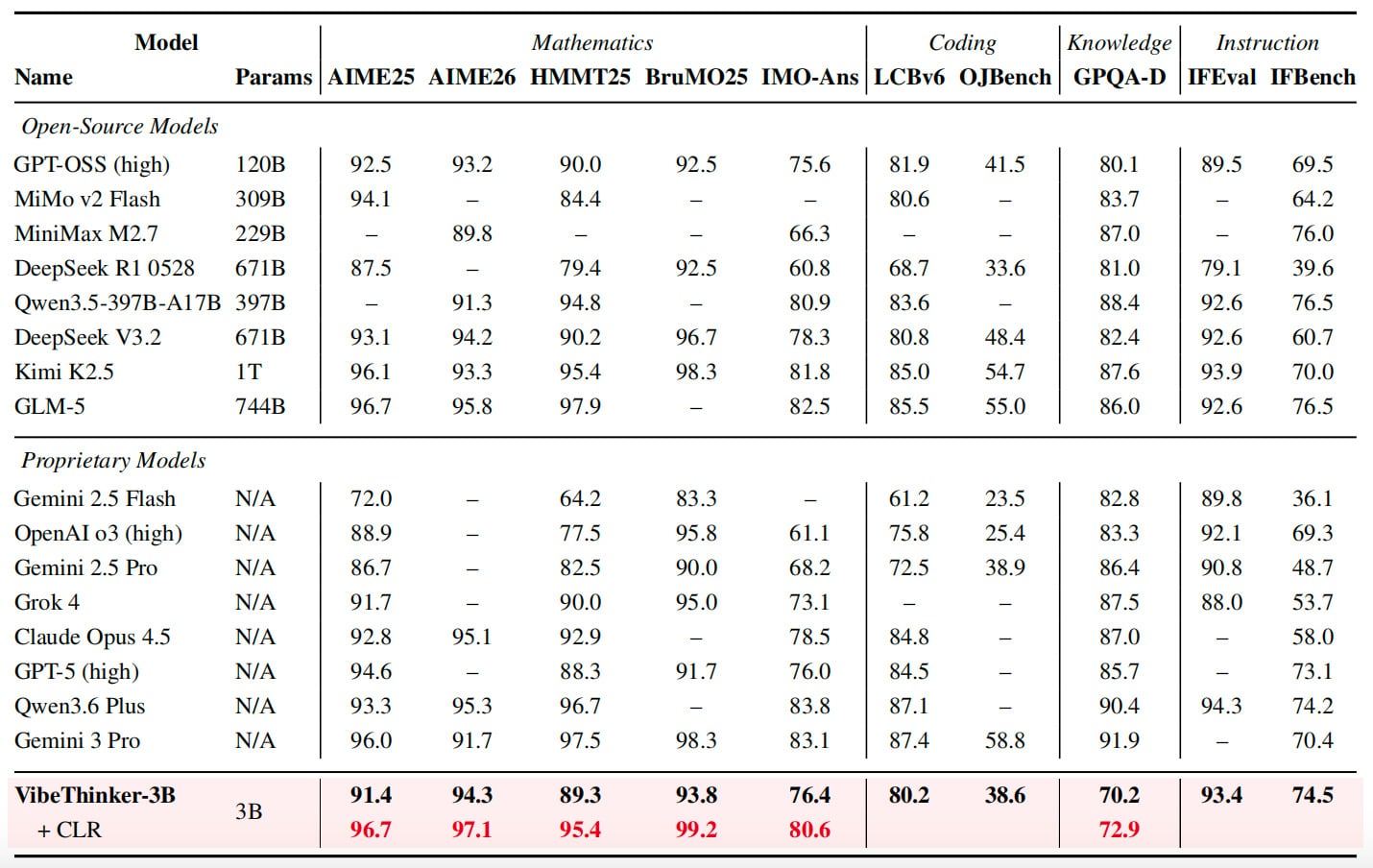
该模型在AIME 2026上获得94.3分,与拥有6710亿参数的深度求索V3.2(DeepSeek V3.2)的性能范围相当,并击败了双子座3 Pro(Gemini 3 Pro)的91.7分。通过一种称为“声明级可靠性评估”(Claim-Level Reliability Assessment)的测试时扩展方法,VibeThinker-3B在AIME 2026上的得分进一步提升至97.1。
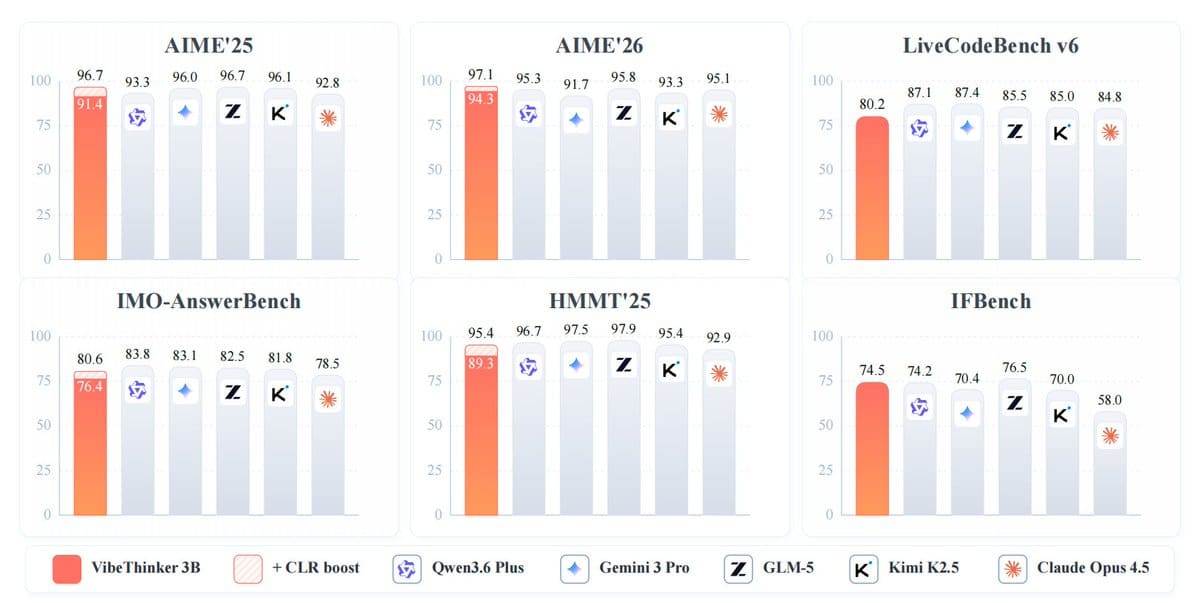
在其他基准测试中,VibeThinker-3B在AIME 2025上得分91.4,在HMMT 2025上得分89.3,在BruMO 2025上得分93.8,在IMO-AnswerBench上得分76.4。编码能力方面,该模型在LiveCodeBench v6上实现了80.2的Pass@1分数,并在2026年4月下旬至5月下旬举行的未见过的LeetCode周赛和双周赛中,获得了96.1%的提交接受率。在指令遵循测试IFEval上,其得分为93.4。
该模型在128次首次提交的LeetCode题目中通过了123次,在相同评估条件下超越了GPT-5.2、豆包种子2.0 Pro(Doubao Seed 2.0 Pro)、Kimi K2.5和克劳德Opus 4.6(Claude Opus 4.6)。
VibeThinker-3B的参数量约为深度求索V3.2(DeepSeek V3.2)的224分之一。相比之下,GLM-5拥有7440亿参数,而Kimi K2.5超过一万亿。该模型足够小巧,可在消费级笔记本电脑上运行。研究团队认为,可验证的推理任务(如数学和编码)能比广泛的事实知识更有效地压缩到较小的模型中,并将此称为“参数压缩覆盖假说”。
该模型并非在所有领域都表现优异。在GPQA-Diamond测试中,其得分为70.2,而双子座3 Pro(Gemini 3 Pro)为91.9,克劳德Opus 4.5(Claude Opus 4.5)为87.0。研究团队表示,这支持了他们的论点:紧凑型模型可以在可验证推理任务上表现强劲,但无法取代提供更广泛知识覆盖的大型模型。
VibeThinker-3B基于阿里巴巴的通义千问2.5编码者3B(Qwen2.5-Coder-3B),并通过四阶段后训练流程进行改进。第一阶段使用监督微调,针对数学、编码、STEM推理、对话和指令遵循数据进行,随后转向更难、更长的推理问题。训练样本中,推理痕迹短于5000个token的样本被移除,同时早期版本VibeThinker-1.5B能解决超过75%的问题也被移除。第二阶段通过最大熵引导策略优化(MaxEnt-Guided Policy Optimization),在数学、编码和STEM任务上使用强化学习。研究人员使用了单个64000 token的窗口,而非逐步扩展上下文窗口,因为渐进式扩展在3B规模上降低了性能。一个独立的“长到短数学强化学习”(Long2Short Math RL)阶段奖励更短的正确答案,以减少不必要的冗长。第三阶段将来自强化学习检查点的成功推理痕迹蒸馏回统一模型。最后阶段使用基于规则的检查和奖励模型,对指令遵循任务应用强化学习。
测试结果引发了关注,但也带来了关于模型可能针对基准测试过度优化的担忧。有用户报告称,该模型在实际编码问题上表现较弱,包括对常用开发工具的困难。还有人质疑为何未在更广泛的软件工程基准上测试该模型。研究人员表示,训练数据经过了严格的基准去污染处理,包括过滤重叠文本。最近的LeetCode竞赛提供了更强的数据泄露防护,因为这些竞赛发生在任何可能的训练截止日期之后。然而,用户报告仍然表明基准得分与实际性能之间存在差距。
该模型根据MIT许可证发布,其权重可通过拥抱脸(Hugging Face)和模型库(ModelScope)获取。发布首日内,开发者就已生成了GGUF量化版本和衍生模型。
新浪微博更以其社交媒体平台而非前沿AI研究而闻名。VibeThinker-3B是该公司在七个月内第二次主要的开源AI发布。2025年11月发布的VibeThinker-1.5B,据称在多项数学基准上击败了原始的深度求索R1(DeepSeek R1)。该团队表示,其后训练成本为7800美元,而深度求索R1(DeepSeek R1)的估计成本为29.4万美元。
研究人员未声称VibeThinker-3B可取代大型通用模型。他们认为,在混合AI系统中,小模型可处理推理工作,而大型系统提供事实知识。这种方法可降低部署高级推理的成本,并在硬件有限的设备上提供强大的数学和编码能力。关键问题在于模型的基准性能能否转化为可靠的现实世界应用。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com









