
维度网讯,阿里巴巴研究人员开发出名为SkillWeaver的框架,用于解决AI智能体在多步骤任务中路由工具的难题,该框架通过组合技能路由方法将token消耗降低了超过99%。
企业AI系统在扩展时,智能体需处理大量工具和技能,现有单技能选择方法难以应对需多步骤执行的业务请求,如“下载数据集、转换数据并创建可视化报告”。研究团队将此类问题定义为“组合技能路由”,要求智能体同时确定如何分解任务、如何将子任务映射到技能以及如何组合成可执行计划。
SkillWeaver通过分解、检索和组合三个阶段实现这一过程。分解阶段由大语言模型将用户查询拆解为一系列子任务;检索阶段使用嵌入模型为每个子任务从技能库中提取候选工具的短名单;组合阶段评估候选工具的兼容性,创建有向无环图形式执行计划。研究团队还引入迭代技能感知分解(Iterative Skill-Aware Decomposition,SAD)技术,通过反馈循环让大语言模型根据初步检索的技能信息重写分解,使粒度与工具库对齐。
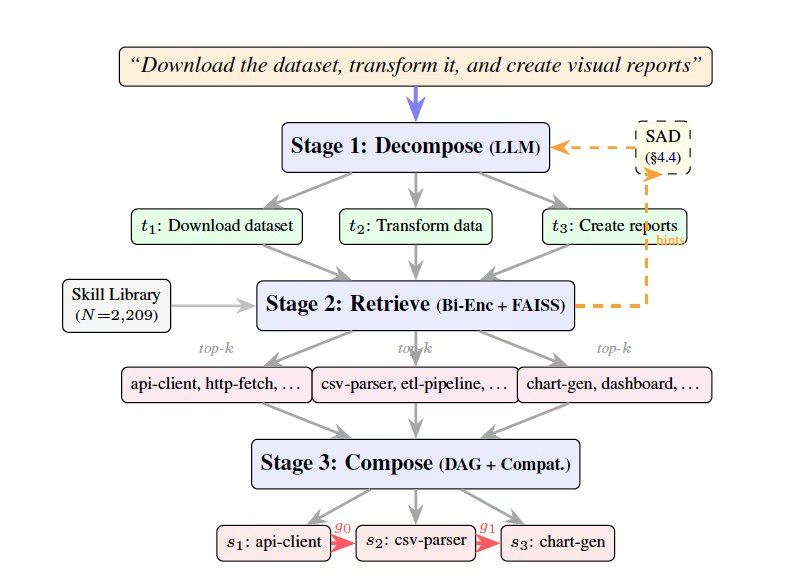
为评估性能,研究人员创建了包含300个多步骤查询的基准CompSkillBench,使用来自公共MCP生态系统的2,209个技能库,覆盖云基础设施、金融、数据库等24个功能类别。核心引擎使用Qwen2.5-7B-Instruct模型进行任务分解,MiniLM语义搜索检索器查找工具。实验显示,在无SAD的普通设置下,7B模型分解准确性为51.0%,激活SAD反馈循环后跃升至67.7%,更大模型Qwen-Max达到92%。在需要四到五种技能的困难任务上,SAD将准确性提升50%。与将所有工具暴露给模型的LLM-Direct方法相比,SkillWeaver的检索再路由显著提升准确性,并将每次查询的上下文窗口消耗从约884,000token降至约1,160token,减少99.9%。
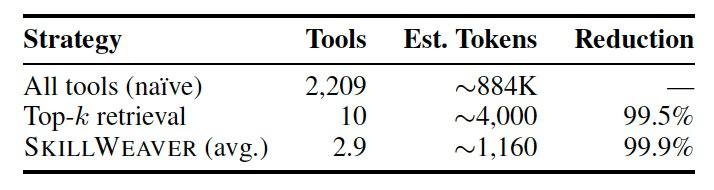
研究团队指出,该框架基于现成开源组件构建,包括all-MiniLM-L6-v2嵌入模型和FAISS索引,对2,209个技能进行嵌入和索引只需15秒。开发者可使用LangChain、LlamaIndex等编排库自行实现。目前SkillWeaver的执行阶段尚缺乏错误恢复能力,在第二步API调用失败时会导致链中断,团队建议生产部署需自行构建回退和重试机制。









