

由Alex Lew教授参与撰写的一篇论文,被选为今年10月在蒙特利尔举行的语言建模会议(COLM 2025)的四篇“杰出论文”之一。该论文题为“基于自适应加权拒绝采样的语言模型快速控制生成”,提出了一种更快、更准确的算法,用于从语言模型生成结构化文本,研究成果已发布在arXiv预印本服务器上。
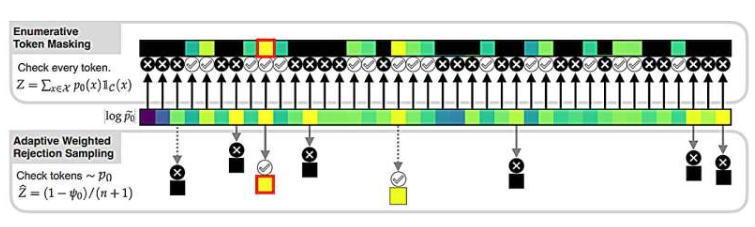
评委们评价称,该论文提出了一种快速、有原则且自适应的受控生成采样器,有效解决了让大型语言模型遵守严格约束条件并快速实现的问题。传统方法“局部约束解码”虽能确保模型始终100%遵循约束条件,但过程缓慢且可能过于局部,导致技术上有效但实际结果失真。例如,在生成经济新闻标题时,若限制只能使用五个或五个以下字母的单词,局部约束解码可能无法找到合适的完成方式。
Lew教授及其合作者提出的算法,则能够高效且全局地应用约束。它无需检查每个可能的下一个词,只需检查少数几个词,大大提高了效率。同时,该算法利用计算统计学领域的算法来应用约束,不会扭曲语言模型响应的概率分布。Lew教授表示:“我们采用的方法可以大幅减少所需的约束评估次数,可能只需要评估三个单词就能运行这个算法。”这一算法在从生成有效的Python代码到分子合成等多个领域都展示了加速效果。目前,该算法已作为开源GenLM工具包的一部分实现,为语言模型的应用提供了更广阔的空间。
更多信息:作者:Benjamin Lipkin 等人,标题:《基于自适应加权拒绝采样的语言模型快速控制生成》,发表于:arXiv (2025)。期刊信息: arXiv