
CoreWeave在美国扩展AI云平台,新增NVIDIA Blackwell GPU容量
2026-03-23 09:15
收藏
在GTC 2026大会上,美国AI云服务提供商CoreWeave确认了其平台的持续扩展计划。公司宣布新增基于英伟达Blackwell GPU的算力容量,并进一步扩大区域覆盖范围,以应对全球范围内持续增长的AI计算需求。这一扩展旨在强化CoreWeave作为专注于训练和推理工作负载的高性能基础设施提供商的定位。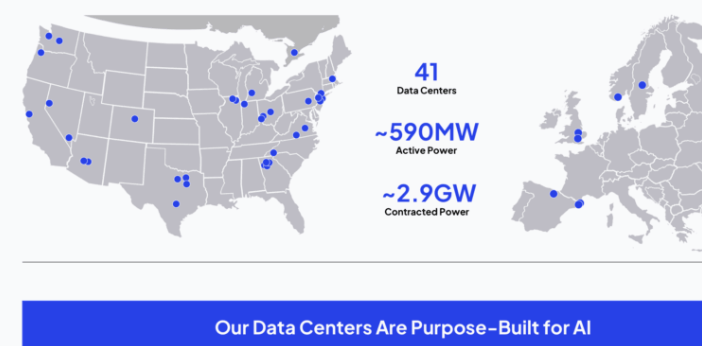
根据披露的信息,此次扩展包括部署额外的GPU集群和配套基础设施,重点支持大规模AI部署场景。CoreWeave强调其平台具备高度的灵活性和快速配置能力,能够根据客户需求动态调配算力资源。平台针对AI工作负载进行了深度优化,集成了对主流机器学习框架的支持,并设计了高速网络架构以最大化GPU利用率,确保客户在处理复杂计算任务时能够获得稳定的性能表现。
CoreWeave的持续扩张,折射出AI云服务市场的结构性变化。传统上,AI算力需求主要由亚马逊AWS、微软Azure和谷歌云等大型云厂商承接。然而,随着生成式AI的爆发,专注于高性能AI基础设施的垂直云服务商正在快速崛起。这类提供商以性能优先、灵活配置和快速交付为特点,吸引了大量AI初创公司和大模型开发团队的青睐。
此次扩展计划也凸显了CoreWeave对市场需求的判断:AI计算需求仍在高速增长,特别是大规模训练集群和低延迟推理场景对算力提出了更高要求。通过提前锁定英伟达Blackwell GPU的供给并加速区域覆盖,CoreWeave试图在专业AI云服务赛道中巩固其先发优势。
随着AI算力需求从“能用”向“好用”演进,云服务商之间的竞争正在从价格战转向性能战。CoreWeave此次在GTC大会上的亮相与扩展计划发布,既是对自身技术路线的展示,也向市场传递出专业AI云服务商正在成长为算力供给体系中不可忽视的力量。
相关推荐

中国移动确认设立Token办公室打通AI服务链
2026-06-29

中国十五五教育规划部署AI全学段教育
2026-06-29

韩国SK电讯2.57亿美元入股SK海力士NAND子公司
2026-06-29

中国华东数控圆台磨床首次获得半导体小批量订单
2026-06-29

中国信通院获批共建“天基智算系统北京市重点实验室”
2026-06-29

中国甬矽电子103亿元扩建高端IC封测三期项目
2026-06-29

中国新石器无人车在泉州设立智达科技公司
2026-06-29

中国无界动力发布具身智能MWA模型,以75.2%登顶RoboCasa
2026-06-29

中国百度昆仑芯拟赴港IPO,估值500亿美元
2026-06-29

美国AWS自7月起上调EC2容量块定价
2026-06-29
最新简讯