

谷歌TurboQuant AI内存压缩技术即将在巴西ICLR 2026展示
维度网讯, 谷歌推出名为TurboQuant的AI内存压缩技术,旨在优化大型语言模型和向量搜索引擎的内存使用。该技术可将内存占用降低约6倍,同时提升注意力计算速度高达8倍,且不损失模型精度。TurboQuant预计将于本月晚些时候在巴西里约热内卢举行的ICLR 2026会议上正式展示。
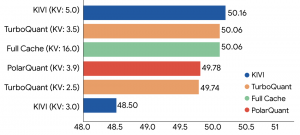
TurboQuant结合了两种互补技术:PolarQuant和QJL算法。PolarQuant通过随机旋转数据向量简化几何结构,实现高质量压缩;QJL则利用约1位的剩余压缩能力消除偏差,确保注意力分数准确。谷歌在博客中表示:“该算法本质上创建了一种高速速记,无需内存开销。”
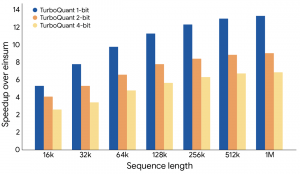
在多项基准测试中,如ZeroSCROLLS和Needle in a Haystack,TurboQuant在保持高精度的同时显著减少了内存使用。测试显示,它能够将缓存精度从16位压缩至约3位,在H100 GPU上实现8倍加速,并提升向量搜索的召回率。
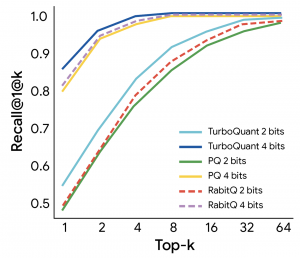
TurboQuant不仅优化压缩效率,还缓解了内存带宽限制,为AI系统扩展提供了新路径。随着模型规模扩大,这种在不影响准确性下降低内存需求的技术,可能成为推动AI发展的关键因素。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告之,本站将予以修改或删除。邮箱:news@wedoany.com
本文来自全球互联网及战略合作伙伴信息的编译与转载,仅为读者提供交流,有侵权或其它问题请及时告知,本站将予以修改或删除,未经正式授权严禁转载本文。邮箱:news@wedoany.com
最新简讯
1
美国苹果AI增强Siri公测版亮相 今秋正式发布
2
美国谷歌8月将推出AI图像编辑器Pics,面向商用和教育用户
3
巴西库里蒂巴拟推社会租赁计划,应对8.4万套住房缺口
4
澳大利亚昆士兰州政府启动670万澳元防洪韧性项目
5
美国曼森工程获1290万美元奥克兰港疏浚合同
6
美国建材公司SRM Concrete收购Troy Ready Mix拓展北卡业务
7
韩国建筑工程企业HS Hwaseong获278亿韩元西归浦港整修合同
8
中建中东公司中标迪拜20公里雨水管网项目
9
英国CMAL启动艾伦港疏浚工程为新建渡轮码头做准备
10
中国三部委印发方案:2030年海水淡化规模达450万吨/日
相关视频





相关推荐

美国苹果AI增强Siri公测版亮相 今秋正式发布
2026-07-17

美国谷歌8月将推出AI图像编辑器Pics,面向商用和教育用户
2026-07-17

美国QTS将在德州霍尔县投资100亿美元建11个数据中心
2026-07-17

瑞士意法半导体发布dToF模块和500万像素CMOS传感器
2026-07-17
中国研究团队提出DPCN多智能体路径规划新范式
2026-07-17

中国摩尔线程2026上半年营收预增135%至149%
2026-07-17

中国海光信息预计上半年净利17亿至18.3亿,营收85亿至93亿
2026-07-17

中国高能光源信创数字基座投运,数据处理效率提升25%
2026-07-17

中国安洁科技2.04亿元收购苏州志烽51%股权
2026-07-17

中国芯原前7月新签146.53亿 算力订单占逾90%
2026-07-17