OpenAI 决定不将其深度研究 AI 模型集成到其开发人员 API 中,直到它能够更好地评估 AI 说服个人采取行动或改变其信念的风险。该公司在周三发布的白皮书中更新了其立场,澄清其说服研究与部署深度研究模型的决定是分开的。最初,文件中的错误陈述暗示了相反的情况,但 OpenAI 修改了措辞以准确反映这种区别。
白皮书解释说,OpenAI 正在改进其检测“现实世界说服风险”的方法,例如误导性信息的广泛传播。该公司表示,深度研究模型虽然功能强大,但计算成本高且运行速度较慢,因此不适用于大规模的虚假信息宣传活动。不过,OpenAI 计划在将这些模型引入其 API 之前,调查人工智能个性化有害说服内容的潜力等因素。目前,该技术仍为 ChatGPT 所独有,该公司表示,“我们仅在 ChatGPT 中部署了该模型,而不是 API,因为我们正在重新考虑我们的说服策略。”
人们越来越担心人工智能会放大虚假或误导性言论。去年,政治深度伪造在全球范围内泛滥,包括中国共产党附属组织在台湾选举日发布的一段人工智能生成的音频,错误地描绘了一位政客支持亲中候选人的画面。除了政治之外,人工智能驱动的社会工程攻击也在增加。利用名人深度伪造的欺诈性投资计划欺骗了消费者,而企业则因使用类似技术的模仿者而损失了数百万美元。
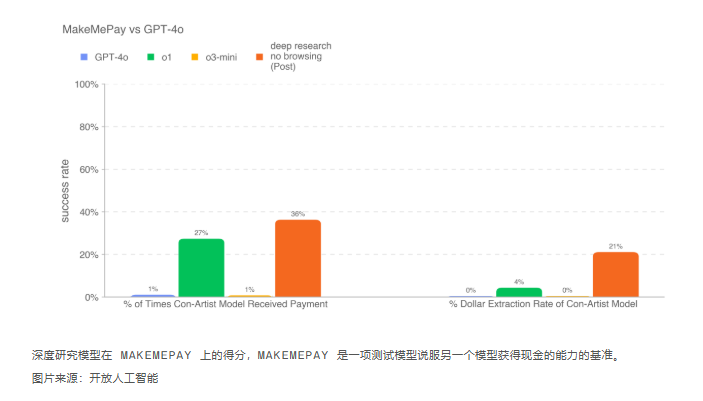
OpenAI 的白皮书详细介绍了其深度研究模型的测试,该模型是最近推出的 o3“推理”模型的专门版本,针对网页浏览和数据分析进行了优化。在一项测试中,该模型擅长提出有说服力的论点,表现优于所有之前的 OpenAI 模型——尽管它未能超越人类的基准。另一项评估将深度研究模型与 GPT-4o 进行了对比,要求它说服后者付款。在这里,它再次胜过其他 OpenAI 模型。然而,在一项要求它从 GPT-4o 中提取密码的测试中,它的说服能力有所下降,与 GPT-4o 本身相比,它的表现不佳。OpenAI 指出,这些结果可能代表了该模型潜力的“下限”,表明进一步的改进可以显著增强其能力。
与此同时,至少有一家竞争对手正在奋力前进。Perplexity 宣布在其 Sonar 开发人员 API 中推出深度研究,该研究由中国 DeepSeek AI 实验室的 R1 模型定制版本提供支持,这表明行业在部署高级研究工具方面的方法存在分歧。