

英伟达DMS技术降低大语言模型推理内存成本8倍
2026-02-13 08:43
收藏
英伟达的研究团队推出了一项名为动态内存稀疏化(DMS)的新技术,可将大语言模型推理过程中的内存成本降低高达八倍,同时保持模型的推理准确性。这项技术通过压缩键值(KV)缓存来实现,该缓存在处理提示和推理时生成,是内存消耗的主要来源。
动态内存稀疏化(DMS)技术智能管理内存,而非简单删除缓存。它训练模型识别关键标记,并采用“延迟驱逐”机制,在短暂保留后清除冗余信息。英伟达高级深度学习工程师皮奥特·纳夫罗特表示:“它不仅仅是猜测重要性;它学习了一个明确保留模型最终输出分布的策略。”这避免了传统方法因丢弃关键数据导致的准确性下降。
DMS的改造过程高效,无需从头训练模型。通过重新利用注意力层神经元,可为预训练模型如Llama 3或Qwen 3添加自压缩功能。纳夫罗特指出:“模型的权重可以被冻结,这使得该过程类似于低秩适应(LoRA)。”例如,Qwen3-8B模型可在单个DGX H100上几小时内完成改造。
在测试中,DMS应用于Qwen-R1系列和Llama 3.2等模型,并在AIME 24、GPQA Diamond和LiveCodeBench等基准上验证。结果显示,配备DMS的Qwen-R1 32B模型在相同内存预算下得分提高12.0分,且吞吐量提升高达5倍。动态内存稀疏化(DMS)还改善了长上下文理解,在“大海捞针”测试中优于标准模型。
英伟达已将动态内存稀疏化(DMS)集成到KVPress库中,支持标准Hugging Face管道,易于企业部署。纳夫罗特说:“我们仅仅触及了可能性的表面,我们预计推理时间缩放将进一步发展。”随着AI系统向复杂推理演进,DMS为降低推理成本提供了可行路径。
本文来自全球互联网及战略合作伙伴信息的编译与转载,仅为读者提供交流,有侵权或其它问题请及时告知,本站将予以修改或删除,未经正式授权严禁转载本文。邮箱:news@wedoany.com
最新简讯
相关推荐

Telxius在多米尼加共和国新增PoP扩展加勒比网络
2026-07-28

印度STT GDC India在斋浦尔推出6兆瓦数据中心
2026-07-28

日本古野电气将于2026年11月发售GNSS接收载板RCB-100
2026-07-28
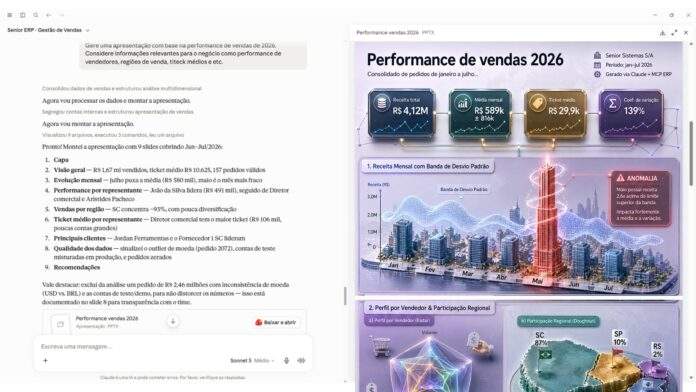
巴西Senior Sistemas推出拉美首个LLM驱动ERP系统
2026-07-28

美国FAA要求2030年底前更换5.85万个高度计防5G干扰
2026-07-28

美国FCC批准C波段频谱,Eutelsat获5.04亿美元
2026-07-28

美国亚马逊Leo申请5105颗卫星直连手机星座2028年部署
2026-07-28
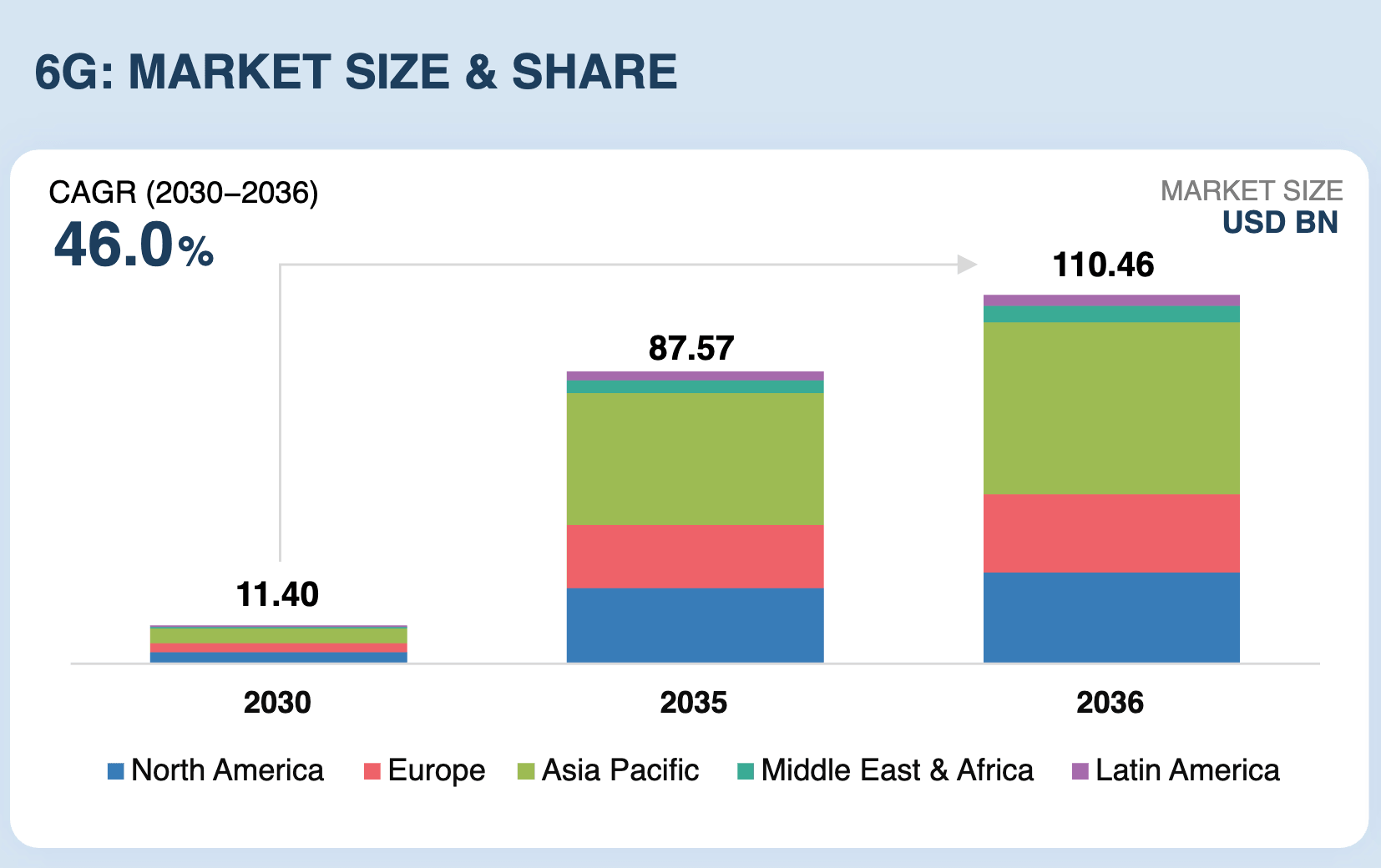
MarketsandMarkets:2036年全球6G市场规模预计超1100亿美元
2026-07-28

西班牙沃达丰与马拉加大学扩大5G卫星网络测试平台
2026-07-28
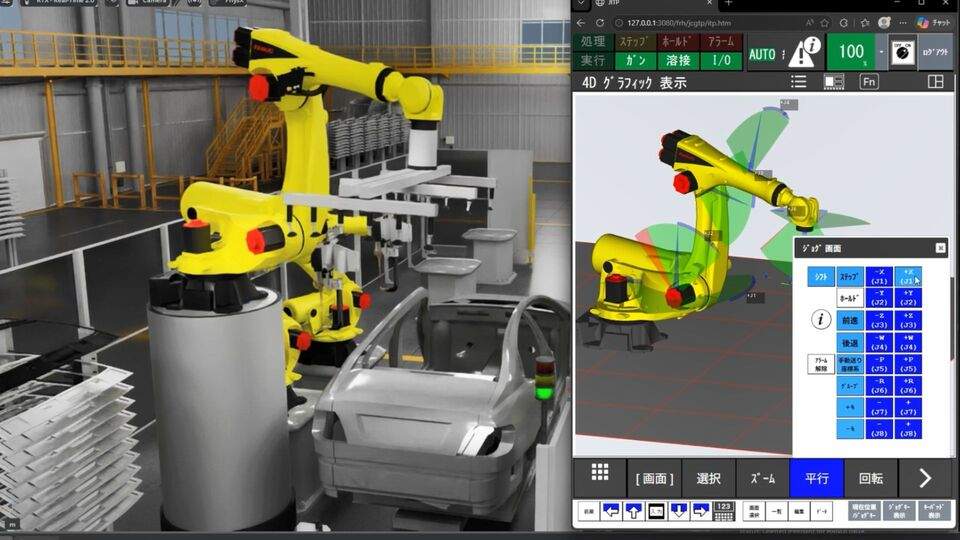
日本发那科与英伟达深化集成 机器人AI计算能力提升7.5倍
2026-07-28