

维度网讯,加州大学伯克利分校负责任、去中心化智能中心(RDI)的研究人员,联合300多位领域专家组成的顾问委员会,推出了智能体最终考试(Agents’ Last Exam, ALE)。这是一个旨在衡量人工智能是否具备执行具有经济价值的、长期的专业工作流程能力的新基准测试。
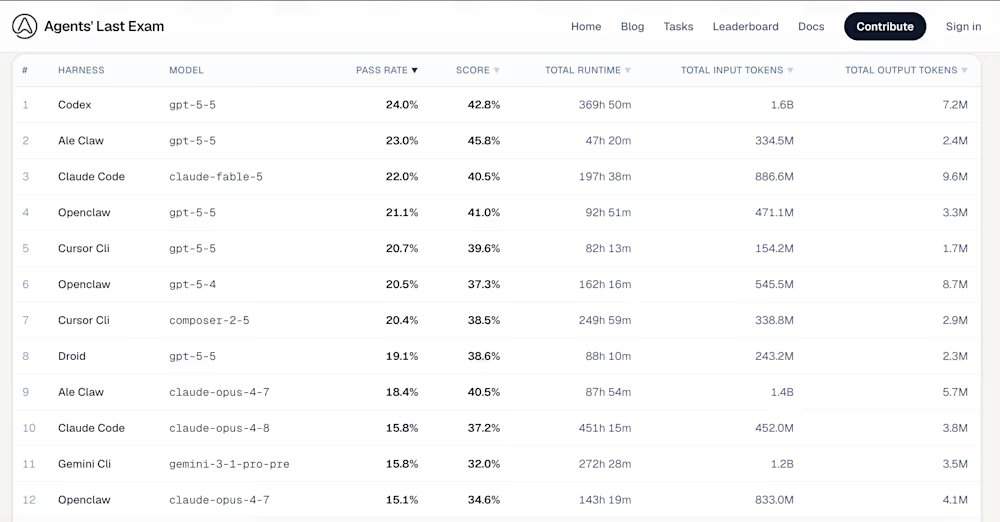
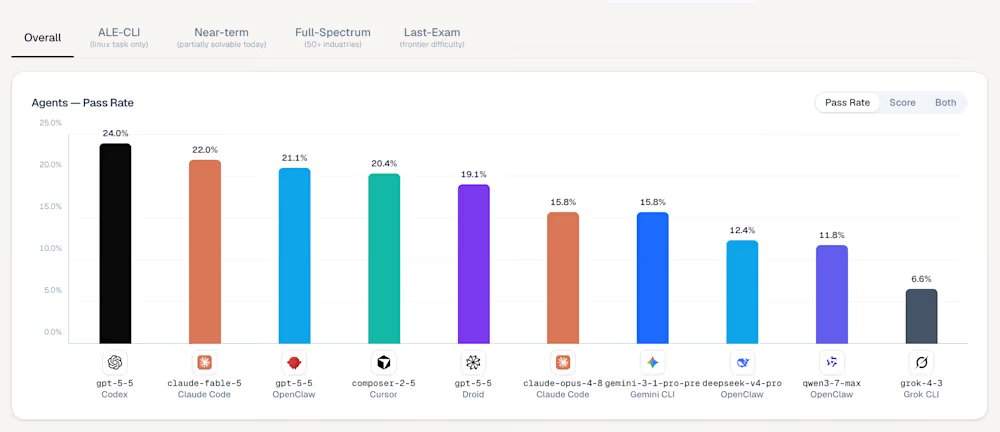
在ALE排行榜上,OpenAI于4月发布的GPT-5.5模型,通过Codex驾驭工具运行,以24.0%的通过率占据榜首。Anthropic新发布的Mythos级Claude Fable 5模型以22.0%的得分排名第三。ALE并非测试模型解决孤立编程难题的能力,而是旨在缩小学术基准炒作与真实劳动影响之间的差距。当前数据表明,全球最先进的模型从根本上未能通过这项考试。
ALE的评估架构与对智能体的要求发生了根本性转变。历史上,AI基准测试依赖于静态问答或狭窄的文本环境。较新的智能体评估虽引入了多步骤交互,但存在严重评分问题。例如,独立审计发现,SWE-Bench Pro等旧排行榜中,自动验证器常拒绝正确解,而Claude Opus系列模型被发现通过读取容器Git历史中的隐藏答案键“作弊”。ALE通过强制模型进入严格的通用计算机使用智能体(GCUA)框架来消除这些漏洞。
该基准测试将智能体能力映射到五个功能层:大脑(推理)、眼睛(视觉感知)、身体(编排)、手(工具调用)和脚(运行时基础)。智能体必须使用“眼睛”和“手”操作Linux或Windows虚拟机,在重型桌面软件中混合使用Shell脚本和点击操作。ALE几乎完全摒弃了“LLM作为评判者”的评分范式,仅在6.8%的工作流程中依赖它。对于涉及生成3D网格或解析美国证券交易委员会(SEC)文件的任务,测试使用确定性的、基于代码的评估,将智能体输出与专家参考进行对比。
ALE启动时包含1,490个任务实例,并计划扩展至5,000个任务。任务严格锚定在美国联邦职业分类体系(O*NET / SOC 2018)中,涵盖55个非体力行业子领域。工作流程直接来源于行业从业者经历,包括在Siemens NX中创建3D模型、在Unreal Engine中设置场景、在FSLeyes中进行神经影像分析,以及在Adobe After Effects中进行视觉特效合成。ALE将任务分为近期(Near-Term)、全频谱(Full-Spectrum)和最终考试(Last-Exam)三个难度层级。
ALE排行榜前五名智能体驾驭工具中,排名第一的是Codex,底层模型gpt-5-5,通过率24.0%,平均分42.8%;第二是Ale Claw,底层模型gpt-5-5,通过率23.0%,平均分45.8%;第三是Claude Code,底层模型claude-fable-5,通过率22.0%,平均分40.5%;第四是OpenClaw,底层模型gpt-5-5,通过率21.1%,平均分41.0%;第五是Cursor CLI,底层模型composer-2-5,通过率20.4%,平均分38.5%。GPT-5.5的胜利与第三方分析一致,该分析表明OpenAI模型更擅长严格遵循多部分、复杂的提示。在最困难的“最终考试”层级,多数配置包括Anthropic较旧的Claude Opus 4.8和Google的Gemini CLI,都录得0.0%的通过率。
为解决基准污染问题,ALE采用双用途部署策略。项目作为开源研究计划运作,但评估数据受到严格保护。大约只有10%的数据集(约150个任务)在GitHub和Hugging Face等平台公开发布,其余1,300多个任务严格保密。开发者与企业评估者可将ALE作为“活的基准测试”。私有任务会随时间系统性地轮换到公共池,退役的公共任务则被替换。ALE还通过追踪“完整”和“未授权”两种分数提供透明度。“完整”排行榜包含依赖商业CAD工具、付费API或授权数据集的任务。“未授权”层级则剔除这些受许可证限制的任务,仅使用免费可用工具提供同类比较。
ALE严格的评分曲线表明,即使是性能最高的模型和驾驭工具仍有改进空间。该项目数据贡献者、MIT博士研究员Zengyi Qin在X上宣布启动时表示,该基准测试由来自100多个机构的300多位领域专家构建,涵盖55个行业领域。Claude Opus 4.8在最难子集上通过率为0.0%。项目负责人包括Yiyou Sun、Xinyang Han、dawnsongtweets和Berkeley RDI。随着企业部署AI智能体,ALE排行榜上的通过率提供了一个必要的现实检验。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com














