
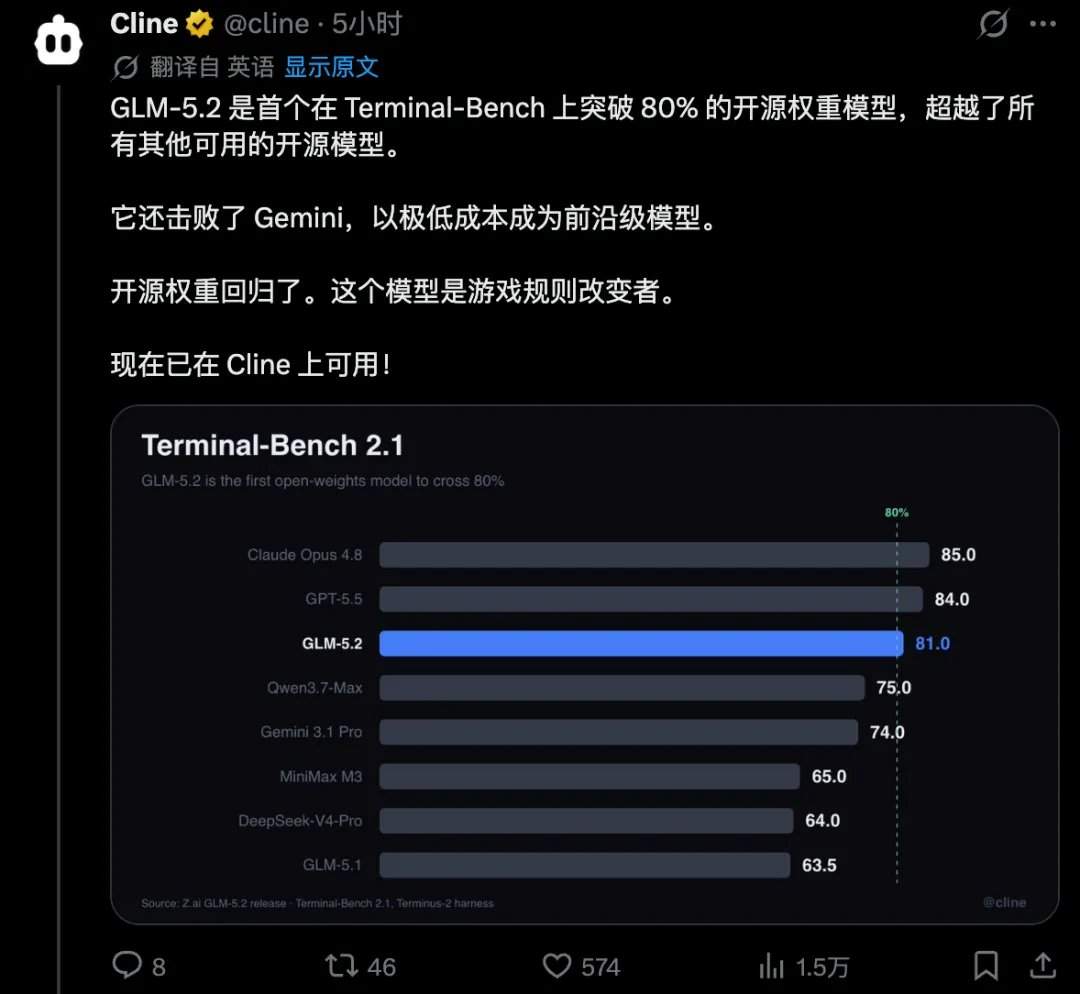
维度网讯,中国智谱AI开发的GLM-5.2在AI编程领域取得较好成绩。该模型在Arena排行榜中排名全球第二,在开源模型中位列第一。在专门评测模型品味的Design Arena上,GLM-5.2获得全球第一。
Arena官方用“令人难以置信的里程碑”来描述GLM-5.2取得的成绩。
在Design Arena上,GLM-5.2取得全球第一的表现。
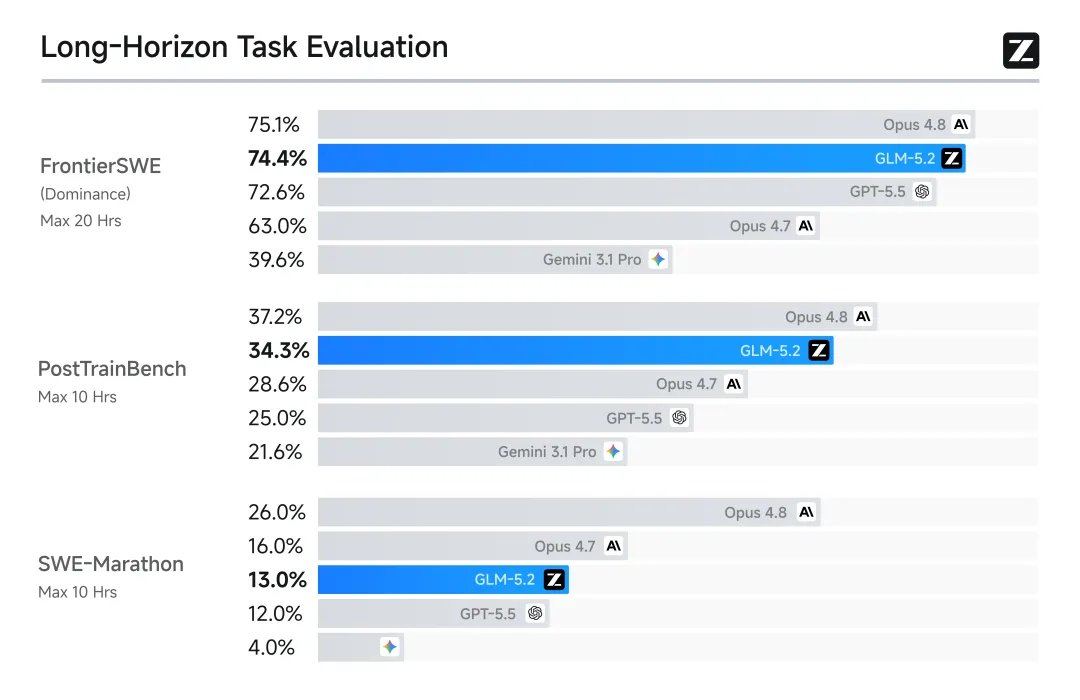
在八项权威基准测试中,GLM-5.2的表现较为突出。
从结果上看,国产开源大模型在Coding领域首次跻身全球前三,与Claude、OpenAI同属第一梯队。此前被广泛提及的谷歌Gemini已被GLM-5.2在榜单能力上替代。
国外博主进行了多项实测,将GLM-5.2与GPT-5.5 High、Opus 4.8 High和Kimi K2.7 Code进行对比。
一位博主认为该测试能较好体现AI实力,GLM-5.2的表现已接近Claude Opus 4.8。另一位博主在实测后表示“This is crazy”。
GLM-5.2支持真正可用的1M上下文,在长程任务中保持领先。这意味着它可以处理大项目级上下文,并跨数小时自主推进。
测试使用了GitHub上的Appsmith项目,这是一个开源低代码平台,用于构建dashboard、admin panel等内部应用。
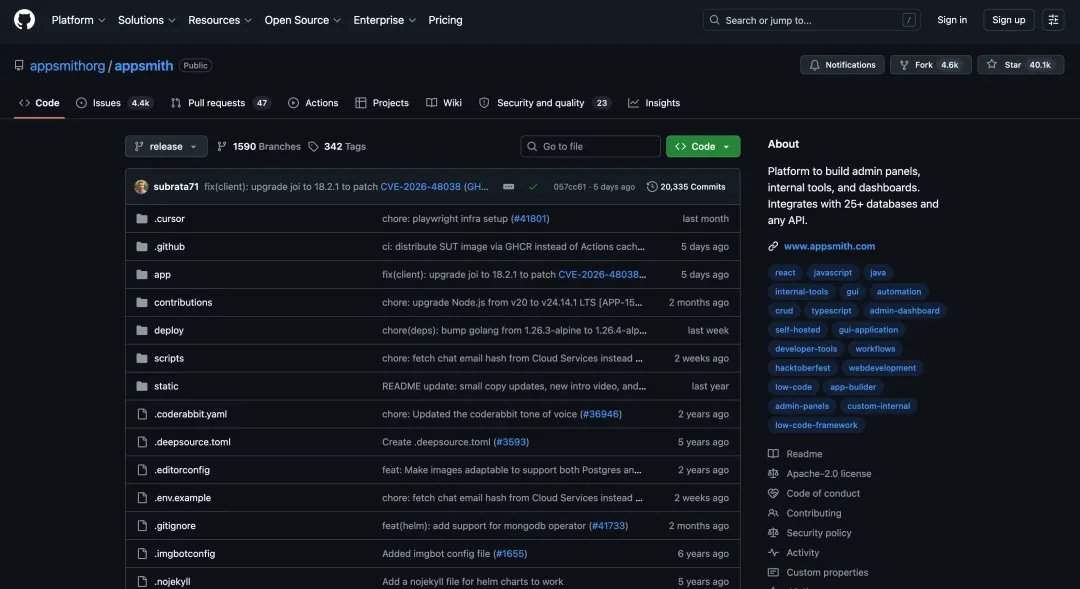
在实际测试中,GLM-5.2在完整代码库理解、跨文件追Bug、新增功能以及多任务处理等场景中表现良好。在Appsmith项目中,它将项目拆解为monorepo结构,精准定位前端、后端及拆分目录,并识别出多个关键耦合点。在OpenWebUI项目中,它成功定位了DirectConnection流式返回的边界问题,并给出修复方案。在新功能测试中,它将“Markdown导出”功能拆分为后端工具、路由、前端API、UI入口和测试五层,并跑通38个后端测试。在多任务处理测试中,它一次性生成了一整套分析报告、表格、图表和脚本。


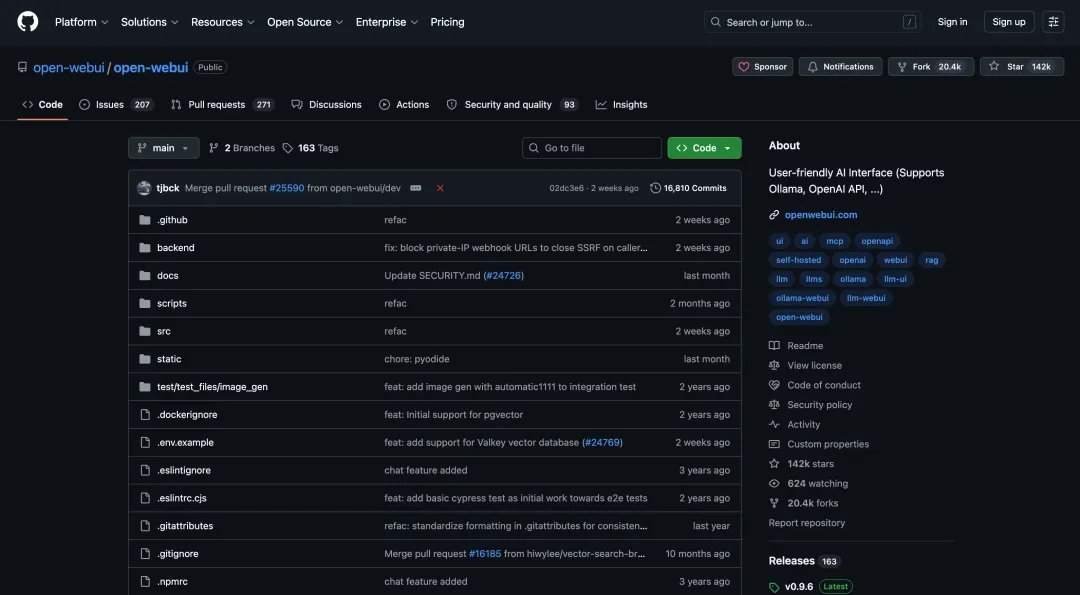

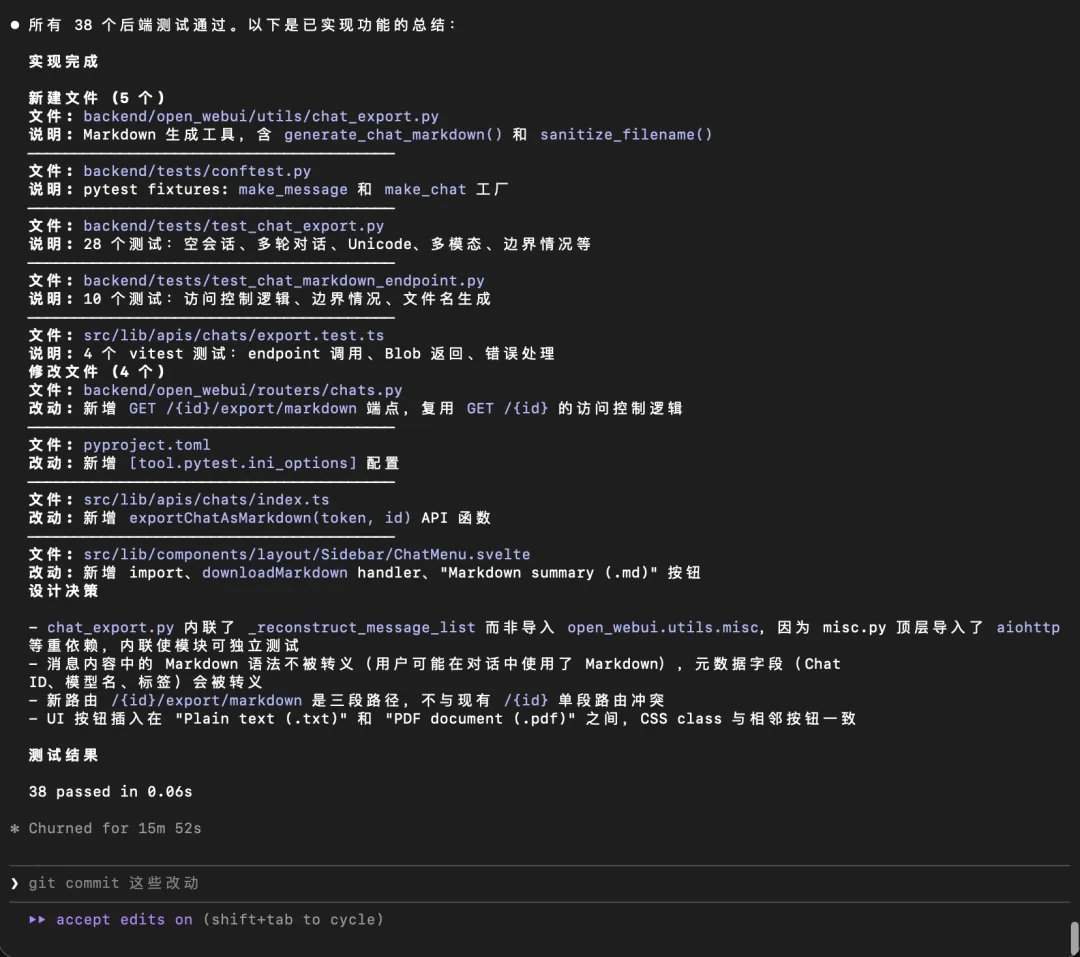

专家指出,AI编程竞争正进入长期工作能力阶段。当前开发者开始将模型放入真实工程流,模型需要读完整项目、理解架构、追踪调用链、保持需求约束、修改多处文件、补测试并生成文档。在此背景下,GLM-5.2代表的开源、长上下文、面向真实工程任务的Coding Agent底座路线,正在形成除Claude Code、OpenAI CodeX之外的第三种选择。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com














