
维度网讯,中国人民大学联合微软研究院推出Arbor框架,将AI系统自主优化从试错过程转变为累积学习机制。该框架通过结构化假设管理,在实际工程任务中实现超过2.5倍的可验证性能提升。

随着大型语言模型和AI系统能力增强,自主优化成为核心挑战。工程团队在优化AI智能体时,常需同时调整分块策略、检索方法、系统提示等多个参数,这些调整相互纠缠,难以精准归因,导致优化过程效率低下。论文合著者Jiajie Jin指出,单纯给编码智能体更多时间或计算资源并不会带来更好结果,“如果目标模糊或指标容易被破解,长时间运行通常只会更快地产生没人真正想要的‘改进’”。
现有编码智能体依赖对话记录作为记忆,但自主优化任务涉及数百轮交互,容易超出上下文窗口限制。智能体难以在长历史中保留事实证据,失去研究过程的整体结构,容易在早期失败上停滞或追逐有噪声的评估波动。同时,通用框架将工具调用链组织在共享工作树上,无法在隔离环境中测试并行假设。
Arbor通过上下分离架构解决这一挑战:协调器作为主研究者,掌握优化研究的全局状态,提出假设并决定实验方向,不直接编辑代码库;执行器是短寿命智能体,在独立git工作树中测试具体假设。两个组件通过“假设树细化”机制协作,将研究过程表示为持久分支树,每个节点绑定假设、可执行工件、事实证据和提炼洞察。协调器在根节点放置宽泛想法,叶子节点放置具体细化,可同时探索多个竞争方向。失败实验被记录为负约束,防止系统重复相同错误。
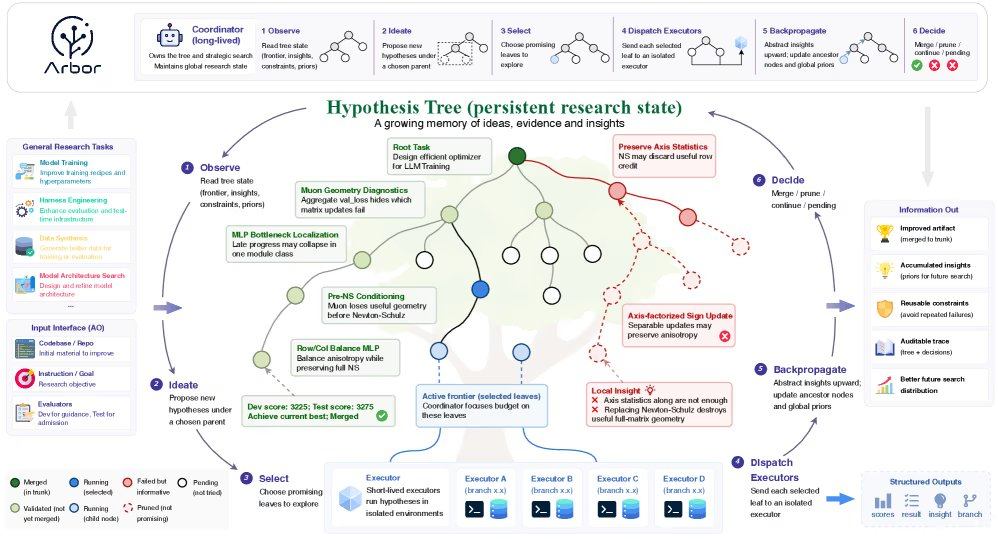
在真实工程场景中,Arbor通过将每个优化杠杆作为单独假设实现了清晰的属性归因。执行器返回报告后,协调器将证据写入树中并将洞察反向传播到父节点。为防止过拟合,框架强制执行“合并门”,在独立工作树中测试候选方案,只有在提升保留测试分数时才合并到当前最佳主干。
研究人员在基于真实研究环境的自主优化任务套件和MLE-Bench Lite机器学习工程基准上评估了Arbor。AO套件涵盖模型训练、框架工程和数据合成等任务。使用Claude Opus 4.6、GPT-5.5和Gemini-3-Flash等骨干模型时,Arbor平均相对增益是Codex和Claude Code的2.5倍以上。在优化搜索智能体的BrowseComp任务中,Arbor将系统保留准确率从45.33%提升至67.67%,而Codex和Claude Code分别停留在50%和53.33%。在MLE-Bench Lite上,配备GPT-5.5时取得最强结果。
Arbor对过拟合展现弹性。在Terminal-Bench 2.0实验中,Claude Code取得75的开发分数但在保留数据上降至71;Arbor开发分数较低为72.22,但取得最高保留分数77.36。跨任务迁移实验显示,优化BrowseComp搜索框架后的代码库可显著提升不相关任务HLE和DeepSearchQA的性能。
该框架设计为构建在现有Git工作流之上。Jin表示,Arbor输出的是普通git分支,现有代码审查和人工审查可直接检查。部署时最大成本为维持协调器和管理树产生的token消耗,以及多个隔离工作树的计算和磁盘资源需求。框架适用于具有明确可信指标、容忍长时间跨度、存在多个合理搜索方向的任务,如管道优化、数据合成质量和模型训练调优,不应用于实时延迟任务、简单修复或评估指标有缺陷的场景。Jin认为下一步演进是将每个节点工件从单一标量分数转向携带准确率、延迟、成本向量的多目标帕累托搜索。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com














