维度网讯,界面新闻采访的三甲医院医生表示,越来越多患者携带AI生成的判断结果前来就诊,增加了医患沟通成本。有医生反馈,一个上午接诊的30个号中,25个患者都带着AI结论。在此背景下,百川智能发布Baichuan-M4医疗增强大模型,该模型基于通用大模型进行结构性重构与医疗专项增强,旨在提升AI在医疗决策中的可靠性。
在最新的HealthBench评测中,M4综合得分68.6,Hard任务得分49.7,幻觉率降至3.3%。在更贴近真实临床环境的HealthBench Professional评测中,M4的基础推理得分为55.1,高于GPT-5.5的51.8分。
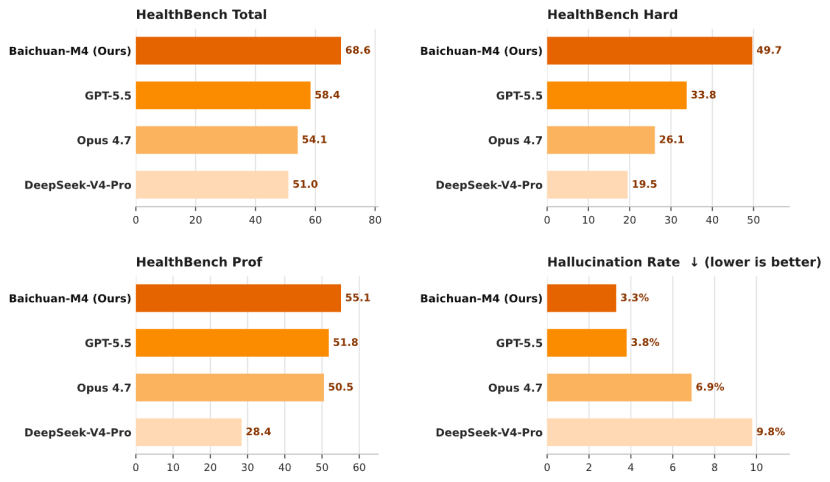
M4的能力提升体现在四个层面。一是动态问诊能力,基于SCAN-bench 2.0体系,模型训练场景从单次标准化问诊扩展到多轮访视与复杂患者画像。在SCAN-bench评测中,M4初诊得分79.0、复诊得分74.7;长上下文临床记忆得分86.9,较上一代M3提升21.1分。二是循证能力,M4构建了原子化临床路径体系,将医学指南拆解为1000余个可复用临床决策单元,覆盖200余种常见疾病的完整诊疗流程。在Baichuan-EBM评测中,循证引用精度达到90.0,显著高于GPT-5.5的54.7。
三是调度能力,M4引入Harness架构,模型可自主决定何时追问、检索证据或调出病史,同时实现在实时安全约束下完成操作。四是全病程记忆,模型可打通历史病历、多轮问诊、化验趋势与用药反馈,在多次对话中掌握患者既往病史与指标变化。
基于M4模型的C端产品百小医已在部分用户中进行内测。该产品可在多轮对话中逐步补齐病史信息,缩小风险判断范围,并在需要时引导用户就医。根据百川智能公布的数据,在中国医学科学院肿瘤医院(肿瘤科)、首都医科大学附属北京儿童医院(儿科)、上海交通大学瑞金医院(呼吸与危重症医学科)等机构的测试中,75个患者群内27天共产生6944条对话,百小医安全性达到99.6%,深度互动率达到60%-73%。

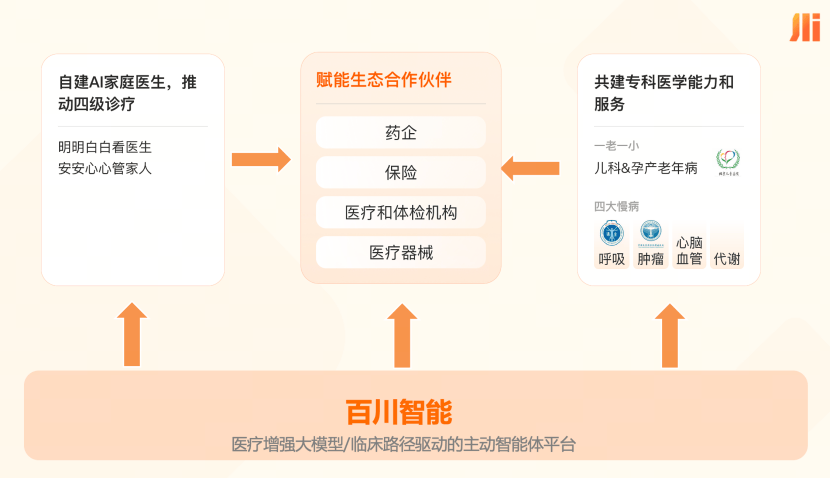
百川智能将M4定位为医疗场景的“大脑”,百小医则为连接用户的“身体”。前者负责专业推理、循证和长期记忆,后者将这种能力送入家庭场景。该公司计划通过“双医模式”让AI负责诊室外的长期陪伴、信息整理和风险提醒,而真人医生则负责诊断与治疗决策。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com