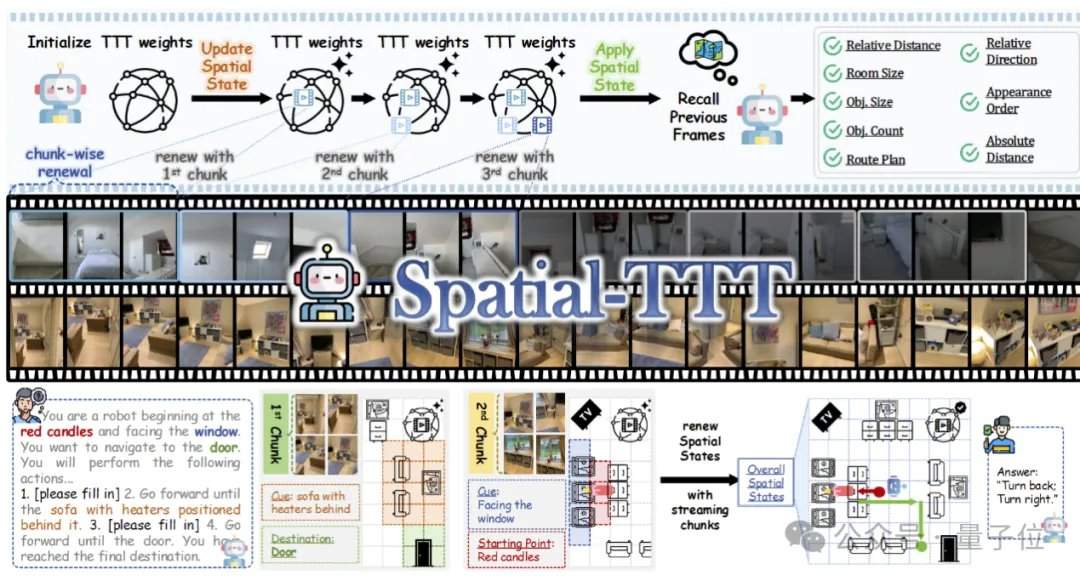
维度网讯,由清华大学博士生刘芳甫担任第一作者、联合多位研究者完成的多模态空间智能工作Spatial-TTT,近日被计算机视觉顶级会议ECCV 2026正式接收。该工作专注于解决多模态大模型在真实物理世界中的流式空间智能难题,即模型如何在持续变化的视频流中形成并不断更新空间记忆,而非每次都将输入视为独立片段。
现实场景如机器人导航、自动驾驶和增强现实,要求模型具备远超静态图像理解的能力。传统方法在处理动辄数十分钟甚至数小时的长视频流时,由于缺乏有效的在线记忆更新机制,导致空间理解碎片化。Spatial-TTT的提出正是为了应对这一挑战,它将测试时训练(TTT)的概念引入空间智能领域,让模型在推理过程中边看视频边更新内部参数。
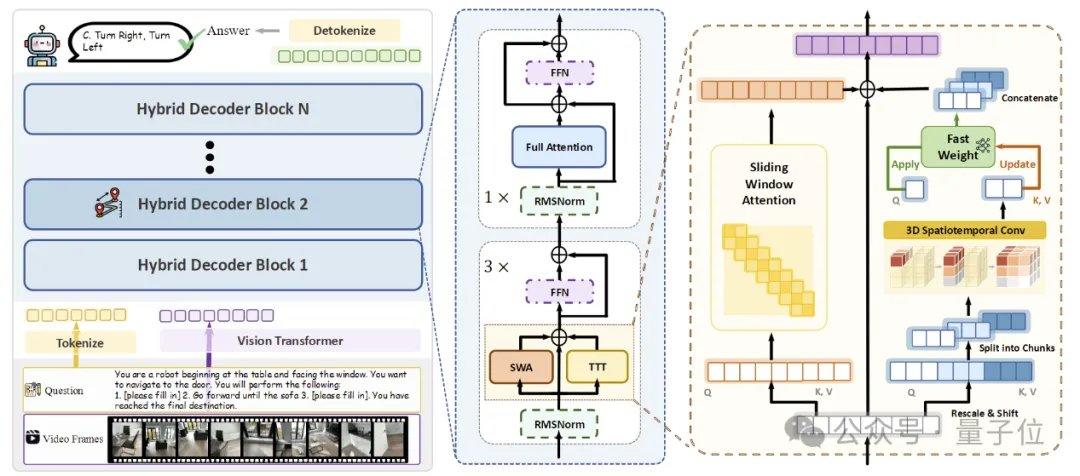
为实现高效的流式空间记忆,研究团队提出了三项关键技术。第一是混合式TTT架构,在解码器中按照3:1的比例交错插入TTT层与标准自注意力锚定层,前者负责将长程信息写入快速权重,后者维持预训练模型的跨模态对齐与语义推理能力。第二是空间预测机制,通过在TTT分支中引入轻量级3D时空卷积,让模型学习时空上下文之间的预测关系,增强在线更新的稳定性。第三是稠密的场景描述监督,通过构建覆盖全局语境、物体类别与空间关系的场景描述数据,训练模型从“局部答题”转向“维护全局3D记忆”。
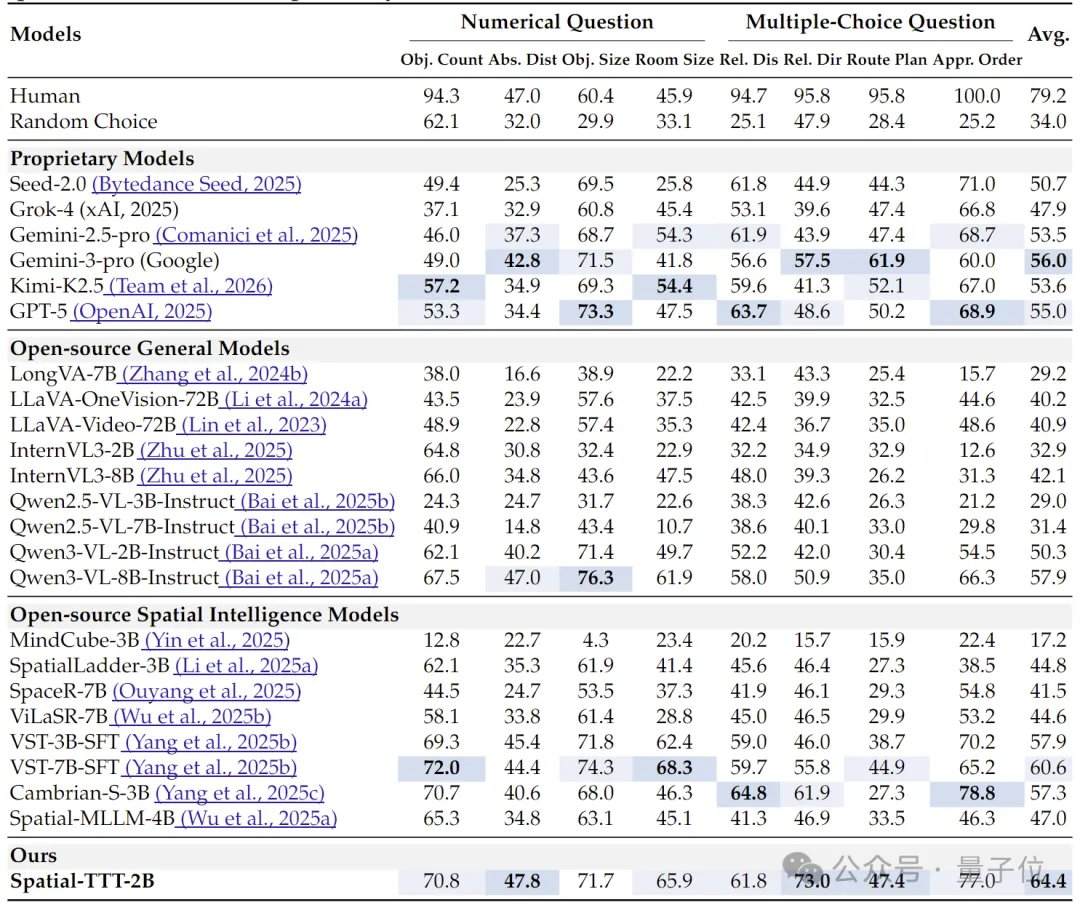
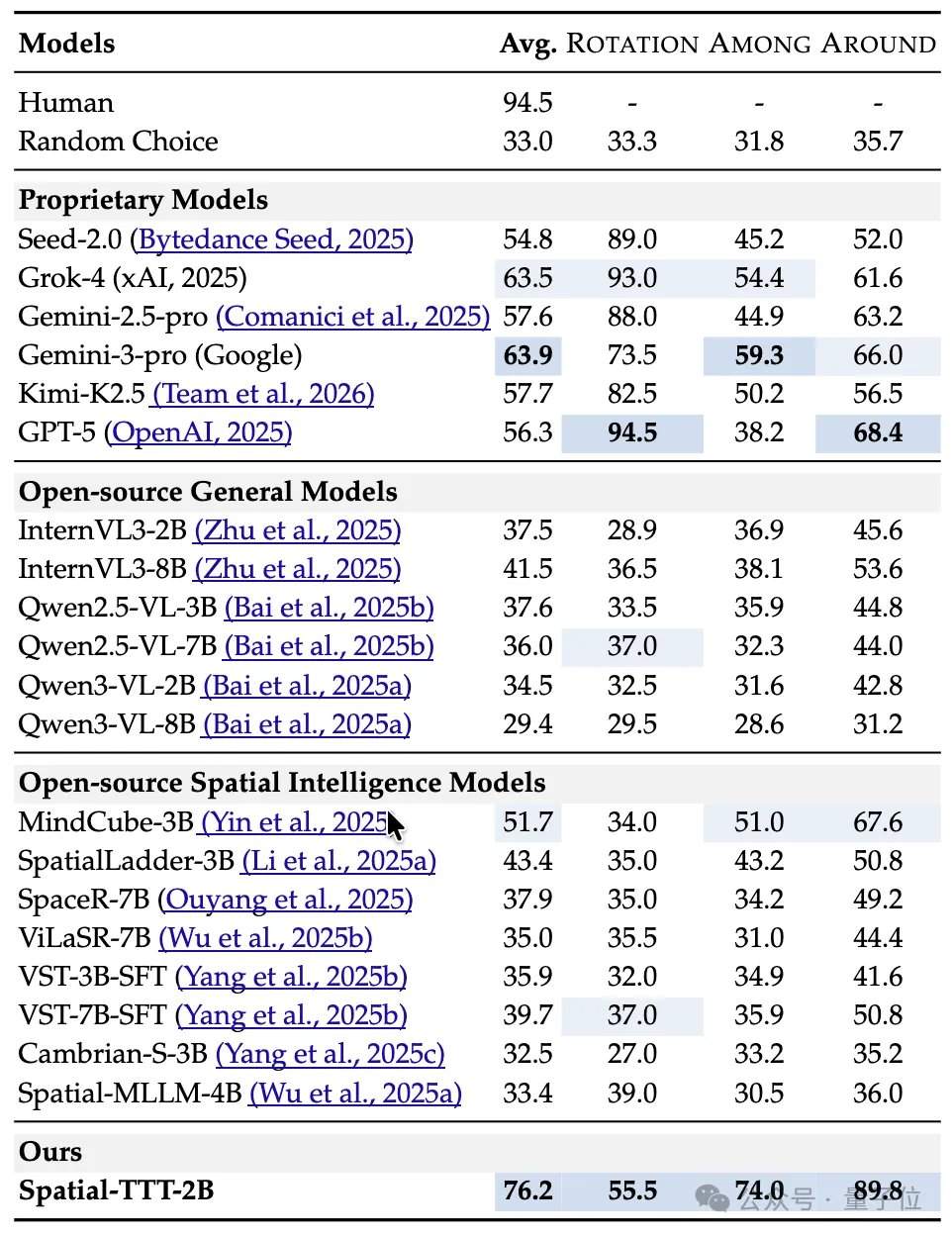
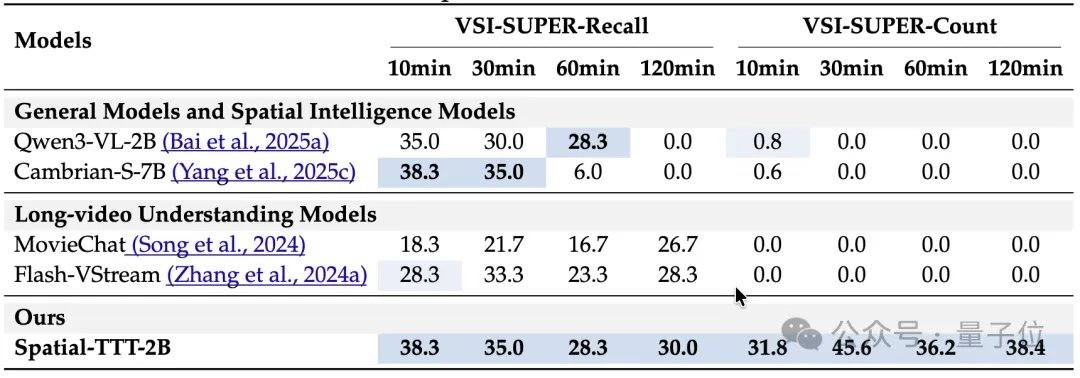
实验结果方面,仅有2B参数的Spatial-TTT在多个专项空间智能基准上展现出显著优势。在VSI-Bench上,其平均得分达到64.4,超越了GPT-5和Gemini-3-pro等闭源模型。在更考验多视角细粒度空间推理的MindCube-Tiny基准上,Spatial-TTT取得了76.2%的准确率,比Gemini-3-pro(63.9%)高出12个百分点,比代表性开源空间模型MindCube-3B(51.7%)高出近25个百分点。在考验长期记忆的VSI-SUPER系列任务中,模型能够稳定处理最长120分钟的流式视频。在VSI-SUPER-Count任务上,Spatial-TTT在10、30、60、120分钟视频上的得分分别达到31.8、45.6、36.2、38.4。
效率分析显示,在1024帧输入设置下,Spatial-TTT-2B的峰值显存占用为11.9GB,理论计算量为799.4 TFLOPs,相比行业领先的基线模型实现了超过40%的显存与计算资源节省。消融实验进一步证实,其性能提升源于混合架构、空间预测机制与密集监督信号三者之间的协同效应。具体表现为:去掉空间预测机制,VSI-Bench平均分从64.4降到62.1;去掉密集场景描述监督,降到61.3;如果完全去掉混合架构、只用纯TTT结构,平均分直接掉到53.9。
此项入选ECCV 2026的研究,为需要长期连续运行的物理人工智能系统提供了新的技术路径。通过让模型持续积累、修正和调用空间信息,未来的智能体将不再面对一帧帧割裂的画面,而是能够构建一个具有连续性、可被理解并作用于其中的内在世界模型。
论文链接:https://arxiv.org/pdf/2603.12255
项目主页:https://liuff19.github.io/Spatial-TTT/
GitHub:https://github.com/THU-SI/Spatial-TTT/
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com