
维度网讯,阿里巴巴Qwen团队发布Qwen-AgentWorld,包含两个模型,它们并非用于在智能体环境中执行行动,而是用于预测这些环境返回的结果,覆盖MCP、搜索、终端、软件工程、Android、Web和操作系统七个领域。
此次发布延续了阿里巴巴近期对自主智能体的投入,5月发布的Qwen3.7-Max围绕35小时自主执行能力构建。团队指出,大规模训练智能体面临的核心瓶颈在于真实环境训练的局限:搜索引擎无法注入受控条件,实时终端不允许按需模拟低磁盘空间等边缘情况,智能体难以系统性地暴露于罕见场景。
研究团队在生成的模拟器中训练智能体,发现其性能提升超过仅基于真实环境训练的效果。另一项测试中,将世界模型训练作为智能体微调前的预热步骤,在七个基准测试中均提升了性能,其中三个基准测试在训练中从未见过。伴随发布的论文指出,世界建模是实现通用智能体的关键环节。
与传统智能体模型优化动作选择不同,Qwen-AgentWorld被训练用于回答相反问题:给定智能体刚执行的操作,环境接下来会显示什么。论文将这一方法称为“语言世界模型”,模型在单一训练目标下学习预测全部七个领域的下一环境状态。此前的相关研究范围较窄,如Qwen在2月发布的WebWorld仅覆盖网络环境;Snowflake在同月发布的Agent World Model生成代码驱动的SQL支持环境,而非训练模型预测状态。Qwen-AgentWorld是首个在单一模型中横跨七个领域,并从最早预训练阶段就融入环境建模的模型。
训练过程使用了来自真实智能体运行的一千多万条环境交互轨迹,分为三个阶段:第一阶段教模型环境运作方式,包括文件系统、终端状态、浏览器DOM变化和API响应;第二阶段训练模型先推理后续状态再进行预测;第三阶段通过强化学习,利用基于规则的检查和开放式质量评分收紧预测。两个模型均采用混合专家设计,每个token仅激活一小部分参数。35B模型激活3B,397B激活17B,两者均支持256K上下文窗口。对于GUI领域(Android、Web和操作系统),模型从文本可访问性树和UI视图层次结构中工作,而非截图。35B模型权重和AgentWorldBench在Apache 2.0许可下可用;397B权重尚未公开发布。
基准测试分数显示了模型预测环境返回内容的准确度,但训练结果揭示了这种预测能力对构建智能体团队的实际价值,这些数字更为重要。据研究人员介绍,在受控模拟中训练的智能体表现优于在真实环境中训练的智能体。注入定向扰动将MCPMark从24.6提升至33.8。在搜索任务中,在完全虚构世界中训练的智能体迁移到真实搜索任务,将开源35B模型上的WideSearch F1 Item从34.02提升至50.31。预热测试显示,世界模型预训练将BFCL v4从62.29提升至71.25,将Claw-Eval从53.60提升至64.88,且无需任何智能体特定微调。
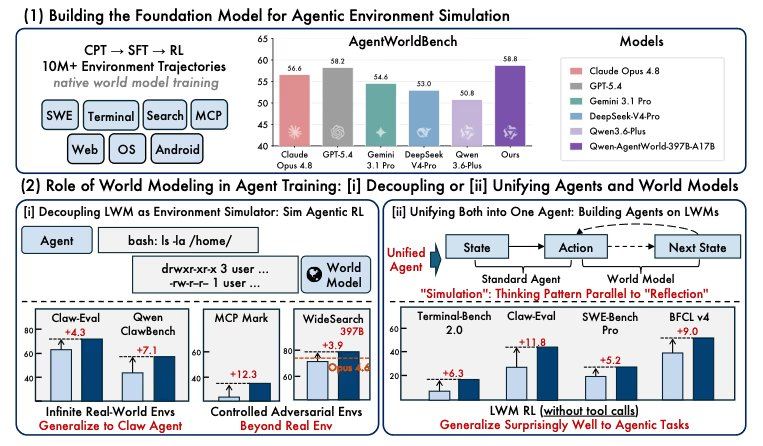
论文发布后引起AI研究者讨论。有观点认为Qwen颠倒了核心问题,训练模型预测环境本身,这种预测知识随后迁移到智能体任务中,即使没有进行智能体特定微调。也有研究者指出,AgentWorldBench是阿里巴巴在同一篇论文中构建并发布的基准,测试中其模型以0.46的差距胜出,可能引发对评估标准独立性的审视。模拟RL方法面临的传统问题是智能体容易过度拟合模拟器的特性,若世界模型过于干净,智能体学习的是模型而非任务。论文中的留出划分和数据结果部分回应了这些担忧,虚构世界的搜索结果表明,在这些环境中训练的智能体可以迁移到真实搜索任务。
对于构建和扩展智能管道的团队而言,这项工作提供了第三种选择:注入生产环境不会出现的边缘情况的受控模拟。合成环境是一种合法的训练层,是真实环境RL的补充,而非绕过它的捷径。在智能体训练前进行环境基础化,比当前大多数实践更早地在开发过程中发挥作用,能够在不需智能体特定训练的情况下提升多个基准测试的性能,模型在训练前所学的内容比大多数管道所考虑的要重要得多。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com









