
维度网讯,来自IMDEA软件研究所(IMDEA Software Institute)、诺基亚贝尔实验室(Nokia Bell Labs)、马德里康普顿斯大学(Complutense University of Madrid)、阿尔托大学(Aalto University)和Quobly的研究人员开发了一种基于FPGA的硬件架构,用于量子LDPC码的实时解码。该设计发表在ArXiv上,通过结构布局管理相关错误阵列,优化延迟、物理面积和功耗,解决了挑战量子纠错层物理扩展的经典计算处理瓶颈。该架构利用有针对性的资源重用循环,而非无限制的硬件并行化,来处理复杂的多量子比特症候依赖性。
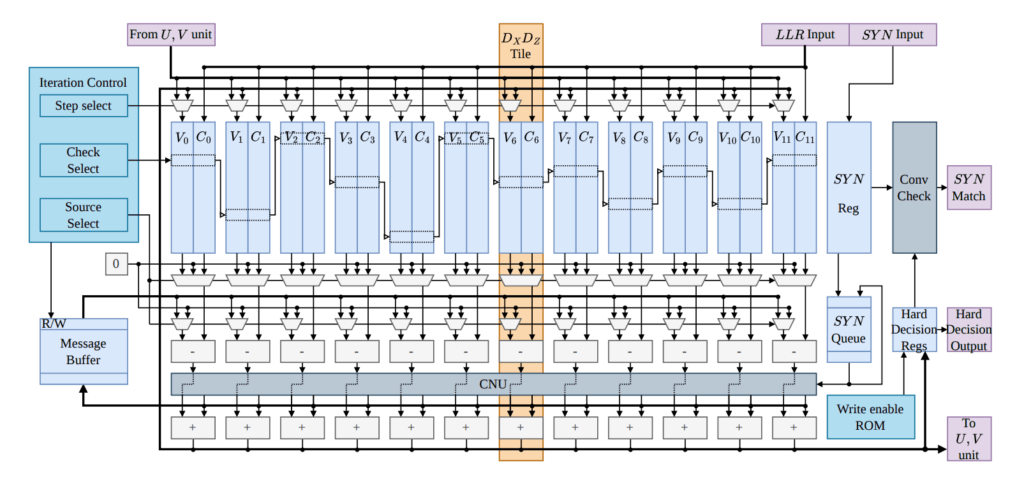
解码器内部布局直接映射到专门的图增强和重连推理(GARI)框架。标准解码例程通常独立处理空间X和Z错误坐标,当相位和比特翻转参数通过组合的Y型故障链接时,会降低跟踪保真度。GARI变换通过分离相关变量并消除涉及Y错误的短4-环,用结构化的U和V坐标依赖性替换纠缠图,从而改变底层检测器错误模型矩阵。这种代数重构允许硬件将联合解码任务分布到解耦的执行路径上,在错误域之间维护迭代信息交换的同时抑制有害消息相关性。
为执行重构矩阵,该架构将处理任务分割为置信传播(BP)核心和并行化跟踪模块。主要的DX和DZ矩阵通过一个基于内存、串行调度的BP单元路由,该单元根据归一化最小和规则顺序更新计算参数。U和V矩阵的独立检查结构在单独硬件瓦片内并行化,与串行核心同步处理间隔。模块化交叉互连使用二进制基数排序阶段作为N对N流水线路由器运行,绕过显式经典控制器逻辑,防止路由拥塞和数据总线停顿。
该硬件实现在AMD VCU19P FPGA上评估,并映射到VU29P FPGA结构,用于在12个连续综合征测量轮次窗口内解码[[144,12,12]]双变量自行车码。该架构应用数值量化约束,将输入对数似然比(LLR)限制为6比特,检查节点消息为8比特,变量节点值为10比特,同时近似经典浮点跟踪模型的数值精度。通过AXI-Stream端口以约274 MHz的运行频率运行,流水线执行循环提供每轮平均解码延迟596纳秒,满足硬件真实相关噪声分布下的实时解码约束。
单个核心占用受限面积,包括总逻辑查找表(LUT)的7.5%、寄存器的3.5%和内部块RAM(BRAM)元素的26%,可部分映射到URAM块以降低内存压力。这一资源效率使得三个解码器组合配置可在单个VCU19P FPGA板内同时运行。24个并发解码器的完整跟踪组合可部署在八个物理硬件设备上,而非完全并行化替代架构所需的48个板。
详细的硅资源分配、矩阵变换推导和路由延迟基准可在arXiv上提供的完整预印本中查看。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com









