

开放分子 2025 是一个前所未有的分子模拟数据集,已向科学界发布,为首次开发能够准确模拟现实世界复杂化学反应的机器学习工具铺平了道路。
这一庞大的资源由 Meta 和美国能源部劳伦斯伯克利国家实验室(伯克利实验室)共同领导的合作项目产生,可以改变材料科学、生物学和能源技术的研究。
“我认为这将彻底改变人们进行化学原子模拟的方式,能够自信地说出这一点真是太酷了,”项目联合负责人、伯克利实验室化学家兼研究科学家塞缪尔·布劳说道。他的团队成员来自六所大学、两家公司和两个国家实验室。
Meta 基础人工智能研究 (FAIR) 实验室研究主任 Larry Zitnick 表示:“我们非常高兴能与社区合作建立这个数据集,并看看它将如何帮助我们创建新的人工智能模型。”
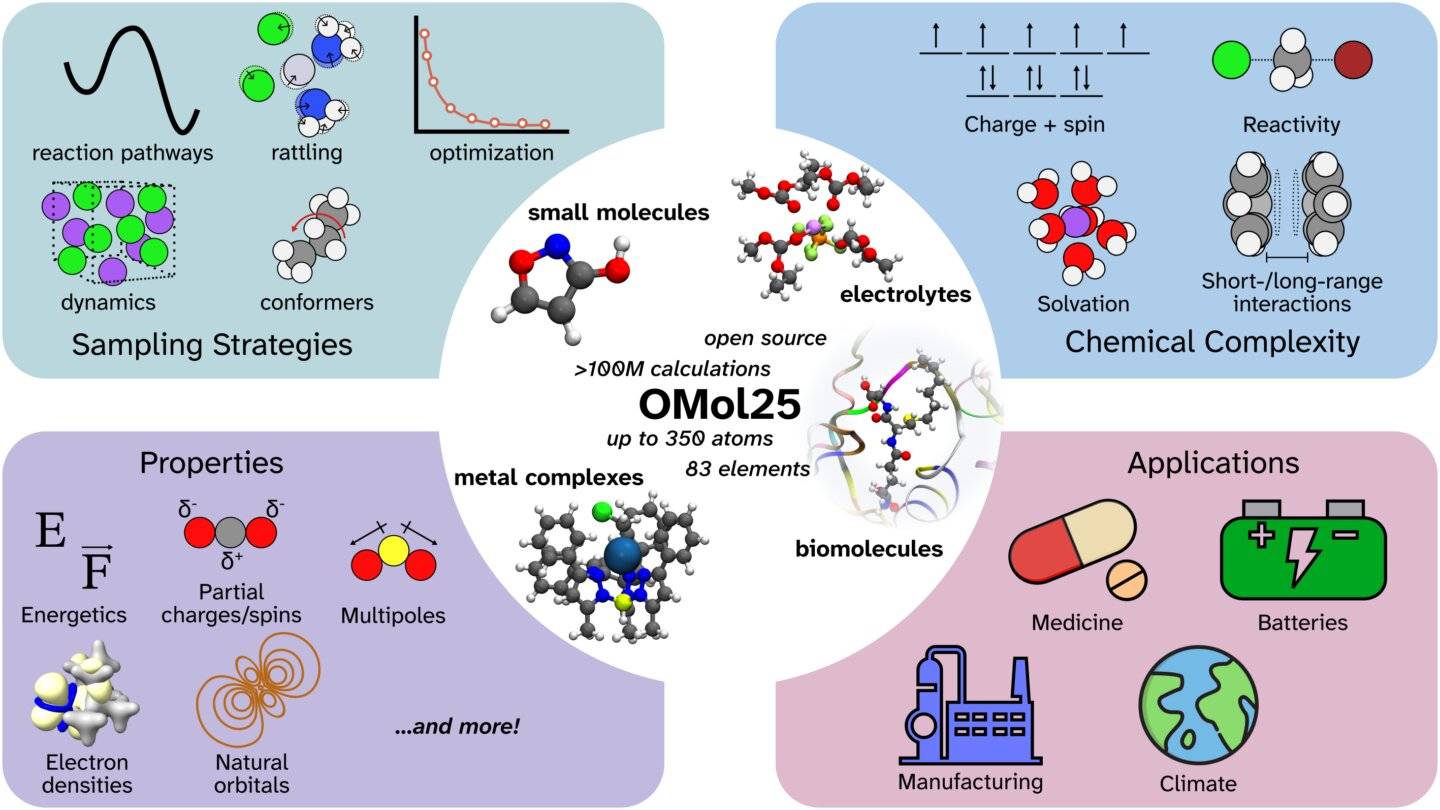
Open Molecules 2025(或 OMol25)是超过 1 亿个 3D 分子快照的集合,其特性已通过密度泛函理论 (DFT) 计算。
DFT 是一种非常强大的工具,可以对原子相互作用的精确细节进行建模,使科学家能够预测每个原子上的力和系统的能量,进而决定分子运动和化学反应,从而决定更大规模的特性,例如电解质在电池中如何反应,或者药物如何与受体结合以预防疾病。
以DFT级精度模拟大型系统的能力将有助于科学家快速设计新的储能技术、新药物等等。然而,DFT计算需要大量的计算能力,而且随着所涉及的分子越来越大,计算量也会急剧增加,即使拥有最大的计算资源,也无法模拟科学相关的分子系统和现实世界中复杂的反应。
机器学习的最新进展为克服这些限制提供了一种方法。基于DFT数据训练的机器学习原子间势(MLIP)能够以快10,000倍的速度提供相同水平的预测,从而能够在标准计算系统上模拟一直以来遥不可及的大型原子系统。
然而,MLIP 的实用性取决于其训练数据的数量、质量和广度。OMol25 是迄今为止用于训练 MLIP 的化学多样性最高的分子数据集。
构建新资源
创建 OMol25 需要非凡的计算能力和 DFT 专业知识。FAIR 团队利用 Meta 庞大的全球计算资源网络运行了数百万次 DFT 模拟,充分利用了全球部分地区用户沉睡而非浏览 Instagram 和 Facebook 的空闲带宽时段。
过去的分子数据集仅限于平均总共 20-30 个原子和少数表现良好的元素的模拟。
OMol25 中的结构比传统模型大 10 倍,也更加复杂,涵盖了多达 350 个原子,涵盖了元素周期表的大部分元素,包括重元素和金属,这些元素的精确模拟极具挑战性。数据点捕捉了涉及有机和无机分子的大量相互作用和内部分子动力学。
“OMol25 耗费了 60 亿个 CPU 小时,比之前任何数据集都要多 10 倍以上。从计算需求的角度来看,使用 1000 台普通笔记本电脑进行这些计算需要 50 多年的时间,”Blau 说道。
人工智能模型的飞跃
世界各地的科学家现在可以开始在 OMol25 上训练自己的 MLIP。他们还可以使用 FAIR 实验室今天发布的开放获取通用模型。该通用模型基于 OMol25 和 FAIR 实验室自 2020 年以来一直在发布的其他开源数据集进行训练,旨在为许多应用提供“开箱即用”的功能。
然而,随着研究人员学会如何最好地利用他们手头的大量数据,通用模型和使用该数据集训练的任何其他 MLIP 预计会随着时间的推移而改进。
为了衡量和追踪模型性能,该合作项目提供了评估,即一系列挑战,用于分析模型在多大程度上能够准确完成实用任务。团队致力于开发极其全面的评估,以使研究人员对基于该数据集训练的MLIP的性能更有信心。
“一旦涉及到原子键断裂和重组以及具有可变电荷和自旋的分子等化学问题,研究人员就会对任何机器学习工具持怀疑态度,”布劳说,他在该项目的这一部分也发挥了重要作用。
评估也通过友好竞争来推动创新,因为结果会公开排名。潜在用户可以查看哪些模型运行顺畅,开发者也可以看到他们的模型与其他模型的比较结果。
“更好的基准和评估对于机器学习许多领域的进步和发展至关重要,”OMol25 团队成员 Aditi Krishnapriyan 补充道。他是伯克利实验室应用数学与计算研究部的科学家,同时也是加州大学伯克利分校化学与生物分子工程、电气工程与计算机科学的助理教授。Krishnapriyan 协助进行了评估并开发了部分化学模拟。
Krishnapriyan 说:“信任在这里尤其重要,因为科学家需要依靠这些模型来产生物理上合理的结果,这些结果可以转化为科学研究并用于科学研究。”
源于社区,服务于社区
OMol25 是由科学家创建的,旨在满足其社区的未满足需求,合作精神贯穿于该项目的各个方面。
为了整理 OMol25 的内容,团队首先从其他人创建的数据集入手,因为这些数据集代表了对不同化学专业的研究人员来说重要的分子构型和反应。然后,他们利用先进的 DFT 功能对这些快照进行了更复杂的模拟。
接下来,他们研究了哪些主要类型的化学之前没有被捕获,并试图填补这一空白。
四分之三的数据集由这些新内容组成,并分为三大重点领域:生物分子、电解质和金属复合物(围绕中心金属离子排列的分子)。仍然需要涉及聚合物(由称为单体的重复单元构成的大分子)的快照。
即将推出的开放聚合物数据将解决这一问题,这是一个补充项目,其中还包括来自劳伦斯利弗莫尔国家实验室的合作者。
OMol25 团队本身是由 STEM 领域中横跨学术界和产业界的分支联系聚集在一起的。Blau 和 FAIR 的联合负责人 Brandon Wood 是在 Kristin Persson 的实验室工作时相识的。Kristin Persson 是伯克利实验室和加州大学伯克利分校的研究员,负责材料项目。Wood、Blau 和 FAIR 化学研究主任 Larry Zitnick 于 2023 年秋季联手开展 OMol25 项目。
他们一起从加州大学伯克利分校、卡内基梅隆大学、纽约大学、普林斯顿大学、斯坦福大学、剑桥大学、洛斯阿拉莫斯国家实验室和基因泰克招募了他们敬佩的科学家。
伍德说:“这个开放数据集是团队出色努力的结果,我们迫不及待地想看到社区如何利用它来探索人工智能建模的新方向。”
布劳补充道:“能够齐心协力推动人类现有的能力发展真的非常令人兴奋。”
更多信息: 分享支持分子特性预测、语言处理和神经科学的新突破和成果。