

意大利理工学院(IIT)和阿伯丁大学的研究人员取得重要成果,为提升机器人空间推理能力带来新希望。他们提出新概念框架与含计算生成数据的数据集,用于训练视觉语言模型(VLM)执行空间推理任务,相关成果发表于arXiv预印本服务器论文,有望推动具身人工智能(AI)系统在现实世界中更好地导航与人类沟通。
该研究是FAIR*项目成果,源于印度理工学院人机交互社会认知(S4HRI)研究线(由Agnieszka Wykowska教授指导)与阿伯丁大学动作预测实验室(由Patric Bach教授领导)的合作。
IIT技术专家、论文共同资深作者达维德·德·托马索(Davide De Tommaso)表示,研究小组聚焦人类与人工智能互动中的社会认知机制运用。此前研究表明,特定条件下人们会赋予机器人意向性,并像与社会伙伴互动一样与机器人交流。因此,了解凝视、手势和空间行为等非语言线索作用,对开发机器人社会认知计算模型至关重要。
视觉视角采择(VPT)指从他人视角理解视觉场景的能力,对机器人系统意义重大,可助其理解指令、与其他智能体合作完成任务。德·托马索称,主要目标是让机器人有效推理其他智能体在共享环境中的感知情况,如评估文本可读性、物体是否被遮挡、物体方向是否适合人类抓取等。尽管当前基础模型空间推理能力不足,但利用大语言模型进行场景理解及合成场景表示,在具身AI代理中建模类似人类VPT能力前景广阔。
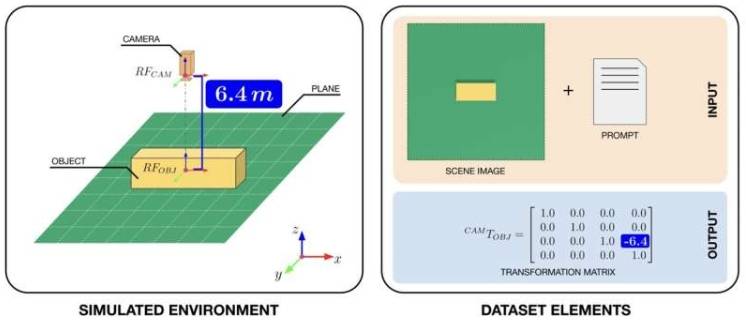
为提升VLM的VPT能力,研究人员编制数据集支持训练。他们借助NVIDIA的Omniverse Replicator平台创建“人工世界”,由可多角度和距离观察的立方体简单场景构成。在模拟世界中捕捉立方体3D图像,为每幅图像添加自然语言描述及4x4变换矩阵(表示立方体位置和方向的数学结构),该数据集已在线发布供其他团队训练VLM。
论文第一作者、阿伯丁大学博士生和IIT研究员乔尔·柯里(Joel Currie)解释,虚拟相机捕捉的每幅图像配有立方体尺寸文本提示和精确变换矩阵,机器人借此规划运动与世界互动。合成环境可控,能快速生成大量图像矩阵对,这是现实场景难以实现的,可让机器人不仅“看”还能理解空间。
目前,该框架尚处于理论阶段,但为真实VLM训练开辟新可能。研究人员可用编制数据集或类似合成数据训练模型评估潜力。Currie称,工作本质是概念性的,提出让人工智能从自身及他人视角学习空间的新方法,将VPT视为模型可利用视觉和语言学习的内容,是迈向具身认知的一步,为机器实现社交智能奠定基础。
De Tommaso、Currie、Migno及其同事的研究有望启发生成更多类似合成数据集,助力人形机器人和其他具身化AI代理改进,推动其在现实世界部署。罗马大学人工智能与机器人专业毕业、新加入IIT S4HRI研究部门的Gioele Migno表示,下一步将使虚拟环境更逼真,拉近模拟与现实距离,这对将模型知识迁移到现实世界、让具身机器人利用空间推理至关重要。之后还将研究这些能力如何使机器人在与人类有相同空间理解的场景中更有效互动。
更多信息: Joel Currie 等,《通过基于空间的合成世界实现机器人的具身认知》,arXiv (2025)。