

加州大学圣地亚哥分校的工程师团队近日取得突破,他们开发出一种新方法,能让大型语言模型(LLM)在更少的数据和计算资源下学习新任务。LLM模型通常由数十亿参数构成,决定其信息处理方式。传统微调方法需调整所有参数,成本高且易导致过拟合,影响模型在新数据上的表现。
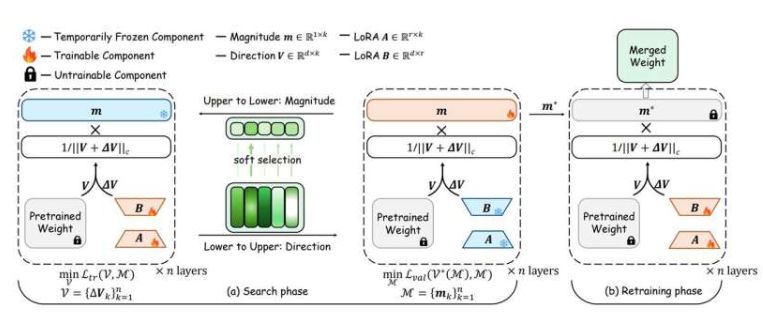
针对这一问题,加州大学圣地亚哥分校的工程师们提出了一种智能的新策略。该方法不重新训练整个模型,而是精准更新模型中最关键的部分。相比现有微调手段,此方法成本更低,灵活性更高,且更擅长将学到的知识泛化到新情境中。
研究团队已证明,即便在训练数据极为有限的情况下,该方法也能有效微调蛋白质语言模型,该模型用于预测蛋白质特性。以预测肽能否穿越血脑屏障为例,新方法在参数量大幅减少(326倍)的情况下,准确率仍超越传统方法。在预测蛋白质热稳定性时,参数量减少408倍的情况下,性能与完全微调方法不相上下。加州大学圣地亚哥分校雅各布工程学院电气与计算机工程系教授谢鹏涛表示:“借助我们的方法,小型实验室和初创公司也能根据自身需求调整大型人工智能模型,无需超级计算机或大型数据集。”
更多信息: BiDoRA:基于双层优化的权重分解低秩自适应算法,《机器学习研究学报》 (2025) 。