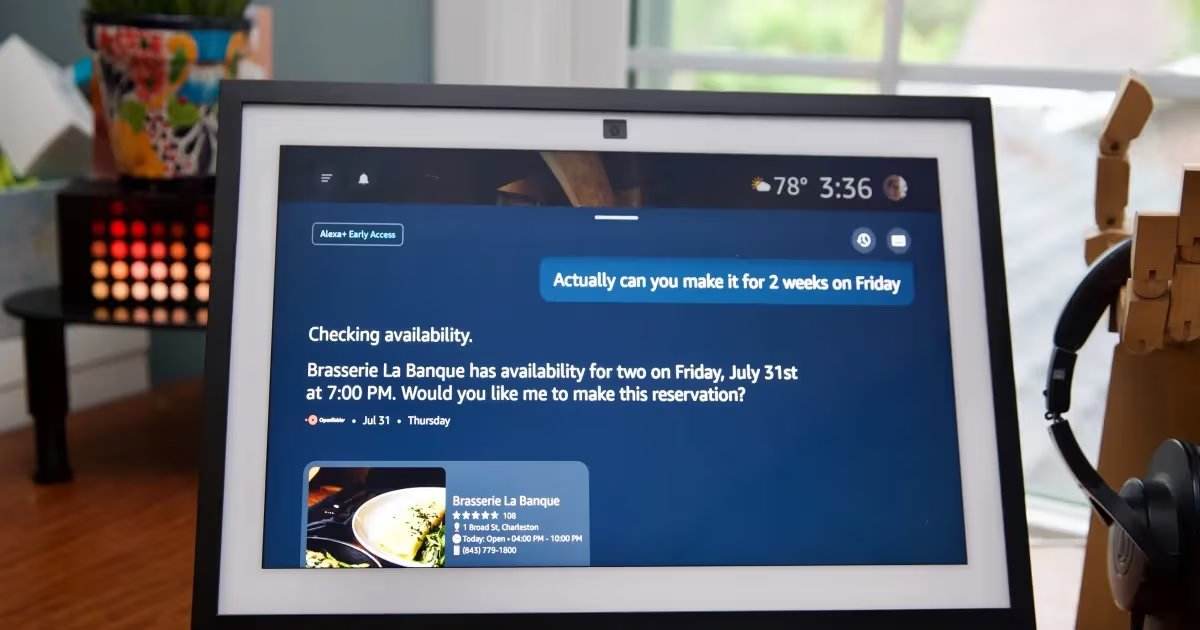
维度网讯,2026年4月12日,摩尔线程AI训推一体全功能GPU MTT S5000完成对新一代大模型MiniMax M2.7的Day-0极速适配,再次验证了中国全功能GPU对前沿AI大模型的快速响应与稳定支撑能力。M2.7是业界首个具备深度自我进化能力的大模型,S5000依托80GB显存、1.6TB/s高带宽及PD分离架构,配合高效KV Cache管理,支撑MiniMax M2.7长时间、多步骤任务的稳定执行。
MiniMax M2.7由MiniMax公司于2026年3月18日正式发布,该模型通过构建Agent Harness(智能体执行框架)体系,深度参与自身训练与优化流程,在部分研发场景中可承担30%至50%的工作量,并在内部评测集上实现约30%的效果提升。在内部测试中,模型可连续执行超过100轮“分析—改进—验证”的循环,自主调整采样参数、优化工作流策略。M2.7能够自行构建复杂Agent Harness,并基于Agent Teams、复杂Skills、Tool Search Tool等能力完成高度复杂的生产力任务。4月12日,MiniMax宣布M2.7全球开源,华为昇腾、摩尔线程、沐曦、昆仑芯、NVIDIA等海内外芯片厂商在开源首日即完成模型接入与推理适配工作。
MTT S5000是摩尔线程专为大模型训练、推理及高性能计算而设计的全功能GPU智算卡,基于第四代MUSA架构“平湖”打造。其单卡AI算力最高可达1000 TFLOPS,配备80GB显存,显存带宽达到1.6TB/s,卡间互联带宽为784GB/s,完整支持从FP8到FP64的全精度计算,是中国最早原生支持FP8精度的训练GPU之一。依托MUSA全栈软件平台,MTT S5000原生适配PyTorch、Megatron-LM、vLLM及SGLang等主流框架。摩尔线程已多次实现大模型Day-0即时适配,此前涵盖智谱GLM-5、千问QwQ-32B及MiniMax M2.5等中国大模型。
MiniMax M2.7的自我进化能力对大模型部署硬件提出了更高要求。模型在自我迭代过程中需持续执行长时间、多步骤任务,硬件系统需在显存容量、带宽吞吐与计算效率之间实现平衡。摩尔线程S5000凭借PD分离架构实现计算与数据处理任务独立调度,高效KV Cache管理机制优化长序列处理场景,确保模型在连续运行中保持稳定性能。此次适配标志着中国GPU与前沿大模型的协同演进进入更紧密阶段。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告之,本站将予以修改或删除。邮箱:news@wedoany.com