维度网讯,Netflix(奈飞)通过引入区间感知缓存策略优化了Apache Druid数据库的查询效率,使约84%的分析结果来自缓存,查询负载降低约33%,P90查询时间改善66%。该优化主要由外部缓存代理层实现,针对滚动窗口仪表盘在连续刷新查询时因时间范围略微偏移导致的冗余计算与大数据集重复扫描问题。
在Netflix的规模下,其实时分析系统需处理数万亿行数据,为监控、实验和运营决策提供仪表盘支持。这些仪表盘频繁执行近乎相同的查询,例如统计滑动时间窗口内的错误率或参与度指标。Hello Interview联合创始人Evan King曾指出,传统缓存将意图相同但时间边界小幅偏移的重复查询视为不同请求,导致缓存复用率低,并在Apache Druid中重复计算。
Netflix的方法将查询结果分解为时间对齐的段,以便在重叠的滚动窗口查询中复用。系统不再缓存完整的查询输出,而是存储固定时间间隔的中间聚合。当新查询到达时,缓存的段被用于时间窗口内相对稳定的历史部分,仅最新时间间隔的数据从Druid重新计算,并与缓存结果合并。
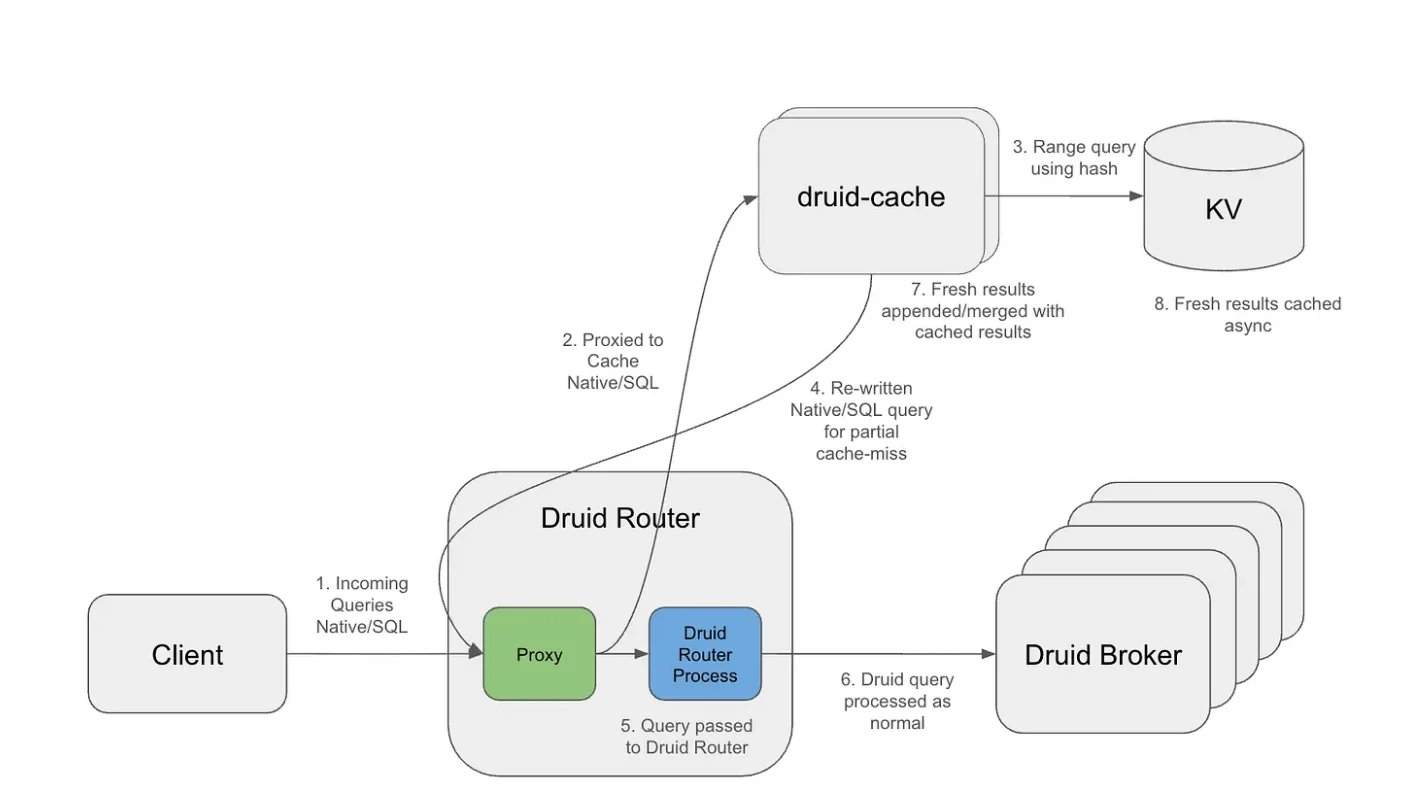
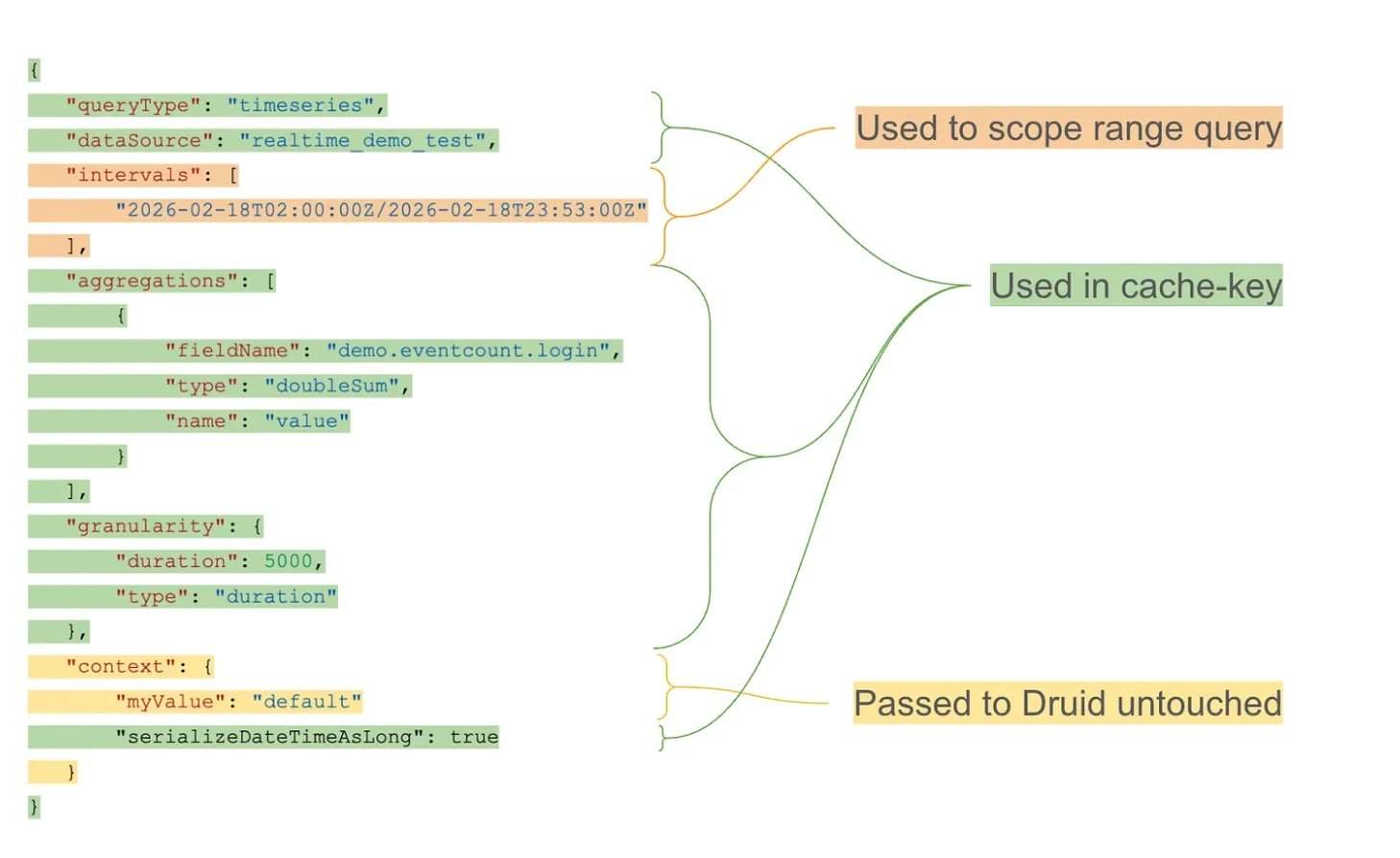
在Apache Druid中超过10万亿行数据的工作负载下,重复的滚动窗口查询成为主要瓶颈。缓存层通过使用粒度对齐的存储桶和指数TTL(生存时间)策略,实现了历史间隔的长期缓存,同时保持最新数据的时效性。在架构上,缓存层作为外部代理运行,拦截传入查询,分离查询结构与时间间隔,生成可复用的缓存键。缓存段存储在分布式键值系统中,支持独立过期和高效检索。
通过这种设计,仅最新间隔需要重新计算,而历史段可在多个重叠查询中复用。因此,到达Druid的查询操作时间范围显著缩小,扫描的段更少,处理的数据量也更少。在某些工作负载中,Netflix观察到结果字节减少高达14倍,段扫描大幅减少。
该系统目前作为实验层部署,并持续演进。未来工作包括扩展支持仪表盘工具使用的模板化SQL查询,以减少对原生Druid查询表达式的依赖。Netflix也在探索将区间感知缓存直接集成到Apache Druid中,以消除外部代理层需求并提高查询规划效率。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com