维度网讯,云知声(Unisound)于2026年6月8日发布其新一代通用大语言模型U2。该模型定位为原生Agent大模型,面向个人、开发者和组织,其技术主张为高智能密度和高Token价值,不盲目堆砌参数或输出长度。
U2与传统偏向单轮问答的通用语言模型不同,强调对真实世界任务的持续执行。在复杂办公、软件工程、深度研究和多工具协作等场景中,U2可自主分解并推进超过100个步骤的工作流,将需求理解、任务规划、环境交互、工具使用、过程修正和结果验证连接成执行闭环,从提供答案转向完成任务。
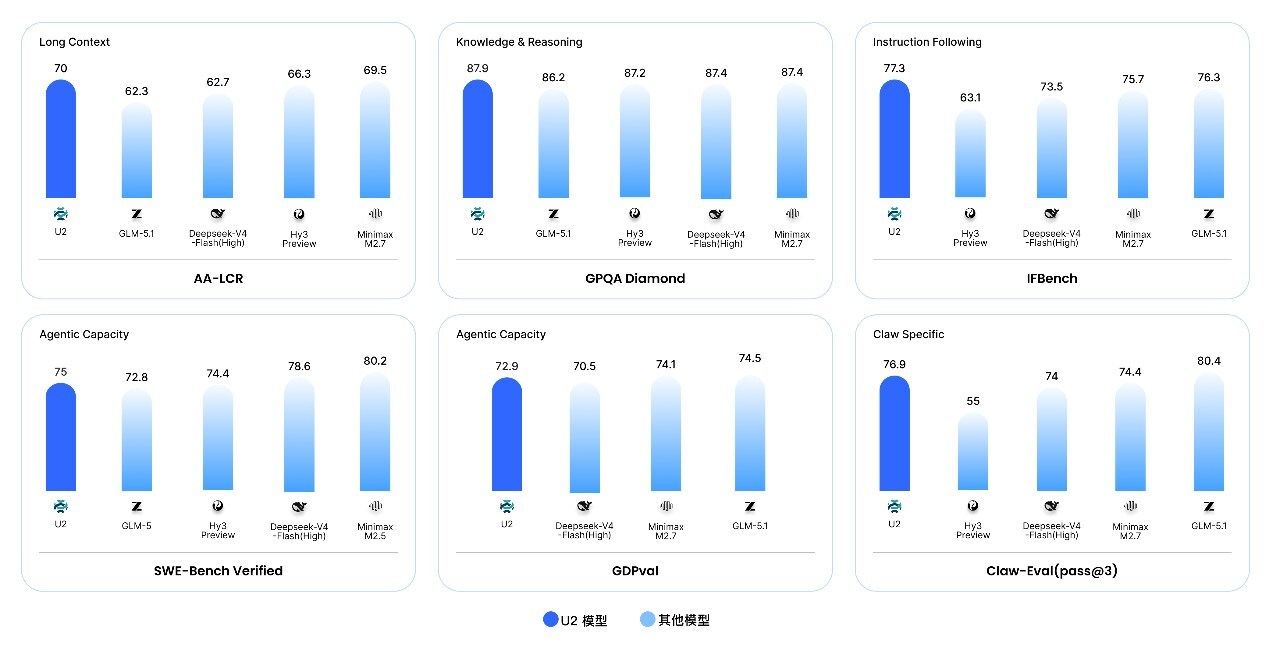
在评测方面,U2在衡量知识和复杂推理能力的GPQA Diamond上得分87.9,超越GLM-5.1、Hy3 preview、DeepSeek-V4-Flash (High)和MiniMax M2.7。在评估软件工程能力的SWE-Bench Verified上得分为75,跻身主流模型顶尖行列。在自主Agent执行端到端评测Claw-Eval (pass@3)上得分为76.9,同样超越Hy3 preview、DeepSeek-V4-Flash (High)和MiniMax M2.7。在评估办公和知识工作交付能力的GDPval上得分为72.9,该基准关注文档分析、报告撰写、电子表格处理、图表生成、幻灯片制作等典型办公任务的完成情况。
云知声表示,U2的设计不是依靠单个孤立能力取胜,而是在推理、编程、Agent执行和办公交付方面提供系统性表现。为实现任务执行目标,U2引入了混合思维机制,在同一个推理过程中根据任务阶段、复杂度和不确定性动态切换显式思维链与潜在空间推理。在任务初期,模型在潜在空间中进行路径搜索、任务分解和候选方案生成;在关键判断或约束处理阶段,则切换到显式推理进行逻辑校准和结果收敛。通过有界潜在推演和熵感知切换,模型可根据推理过程中的不确定性动态调整思维模式。
在知识基础上,U2应用了高知识密度数据筛选与净化技术,过滤重复和低质量数据,并结合稀疏知识编码和知识蒸馏架构压缩冗余模型参数。在任务执行层,引入了Agent-Harness协同训练范式,将模型能力提升与工具链优化纳入同一训练循环,使真实任务中产生的高质量执行轨迹反馈给模型,增强其在规划、工具使用、过程修正和结果验收方面的能力。
U2聚焦推理、编程和Agent三项核心能力。推理方面强调低偏差执行和长期逻辑稳定性;编程方面面向端到端工程交付,能从自然语言需求生成代码并理解多文件项目结构;Agent能力方面致力于提升多工具协作、长流程编排和环境交互。这些能力构成从需求理解、规划执行到协作验证的任务交付闭环。
在应用场景方面,U2可覆盖全谱界面设计,包括响应式网页开发、移动Web应用构建和设计系统实施;深度研究与分析,包括行业与政策研究、数据可视化分析及多格式文档交付;沉浸式交互游戏开发,如经典休闲游戏和物理模拟器;以及高效办公自动化,包括业务报表分析、行业格局分析和周期性业务复盘。U2已在云知声Token Hub上线,向个人、开发者和组织开放。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com