

人类本能地行走和奔跑——快步走感觉毫不费力,我们会自然而然地调整步幅和步伐,而无需有意识地思考。然而,对于实体人工智能机器人来说,掌握基本动作并不一定意味着能够适应新的或意料之外的情况。
即使机器人经过训练可以高速运行,它在面对不同任务时也可能会难以进行细微的调整——例如修改腿部角度或施加正确的力量——这常常导致运动不稳定或停止。
认识到这一挑战,韩国蔚山国立科学技术大学人工智能研究生院的 Seungyul Han 教授和他的研究团队开发了一种开创性的元强化学习技术,使人工智能代理能够独立预测和准备不熟悉的任务。
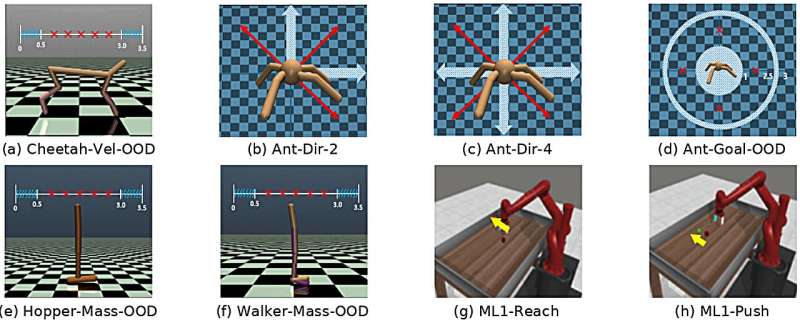
他们引入了任务感知虚拟训练(TAVT)——一种创新方法,使人工智能能够提前生成虚拟任务并从中学习,显著增强其适应不可预见的挑战的能力。
该研究采用双模块系统,包含基于深度学习的表征模块和生成模块。表征模块评估不同任务之间的相似性,创建一个捕捉关键特征的潜在空间。生成模块则合成新的虚拟任务,这些任务反映了现实世界场景的核心方面。这一过程有效地使人工智能能够预先体验尚未遇到的情况,从而提升其对分布式外(OOD)任务的准备程度。
首席研究员 Jeongmo Kim 解释说:“传统的强化学习训练代理在特定任务中表现出色,限制了其泛化能力。虽然元强化学习可以让代理接触多种任务,但适应全新的、前所未见的情况仍然是一个挑战。” 他补充道:“我们的 TAVT 方法可以主动帮助 AI 为此类场景做好准备。”
该团队在各种机器人模拟中测试了TAVT,包括猎豹、蚂蚁和双足机器人。值得注意的是,在Cheetah-Vel-OOD实验中,使用TAVT的机器人能够快速适应前所未有的中等速度(1.25和1.75米/秒),并保持稳定高效的运动。相比之下,传统训练的机器人通常难以适应,导致不稳定或失去平衡。
韩教授强调:“这种方法显著提高了人工智能在不同任务中的泛化能力,这对于自动驾驶汽车、无人机以及在不可预测的环境中运行的物理机器人等应用至关重要。它为更灵活、更具弹性的人工智能系统铺平了道路。”
该研究成果于2025年7月13日至19日在加拿大温哥华举行的国际机器学习大会(ICML 2025 )上发表。论文可在arXiv预印本服务器上获取。这项工作彰显了各方齐心协力推进人工智能核心技术,并为应对现实世界挑战提供创新解决方案的努力。
更多信息: Jeongmo Kim 等人,《任务感知虚拟训练:增强元强化学习在分布外任务中的泛化能力》,arXiv (2025)。期刊信息: arXiv