

现代神经网络参数众多,易对随机无结构数据“过拟合”,但使用结构化数据集训练时,却能学习到数据潜在特征。理解为何过度参数化不破坏模型有效性,是人工智能领域根本性挑战。斯坦福大学安德拉·蒙塔纳里和波兰物理技术研究所皮尔弗朗切斯科·乌尔巴尼提出,特征学习和过拟合虽同时存在,但在训练过程发生于不同时间尺度。
计算机科学起源于艾伦·图灵的开创性工作,其“机器”与“指令”分离架构,是控制多种设备运行的基础。上世纪五十年代,开放式计算框架提出,机器可直接从庞大训练数据集学习必要指令,这标志着范式转变,如自动驾驶汽车通过大量数据训练,学习底层功能,找到驾驶软件,这正是机器学习和神经网络核心概念。人工神经网络训练中自动调整大量可调参数,简单神经网络理论基础是统计学习理论,其核心是网络拟合复杂度相对训练数据量较低时高效运行。然而,约十五年前,深度神经网络实证证明在简单任务上极其有效,尽管权重常比训练样本多,出现过参数化,但能学习有意义数据潜在特征,理解过参数化对神经网络性能影响成为核心问题。
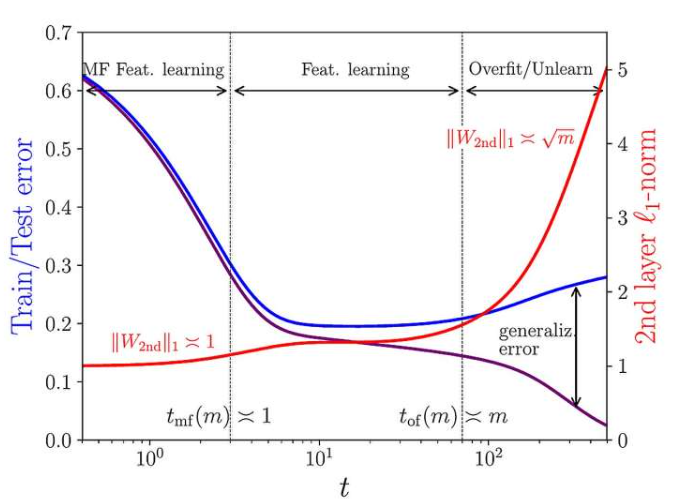
在最近一项研究中,斯坦福大学Andrea Montanari和IPhT的Pierfrancesco Urbani提出解决方案,结合理论物理技术和统计分析,证明过拟合和特征学习在过参数化神经网络中同时存在,但出现时间点不同,即时间尺度分离现象。这种动态解耦源于训练算法和网络架构相互作用,模型越大,分离度越大,特征学习先于过拟合发生,揭示了大型过参数化神经网络工作原理的稳健机制。
更多信息:作者:Andrea Montanari 和 Pierfrancesco Urbani (2025) 标题:大型双层网络中泛化和过拟合的动态解耦。”来源:第三十九届神经信息处理系统年会。