维度网讯,6月1日,中国人工智能公司MiniMax推出新一代通用模型MiniMax M3。该模型基于自研MiniMax Sparse Attention架构,API最高支持1M tokens上下文窗口,并保障至少512K tokens可用,重点面向长程智能体、复杂代码任务和原生多模态应用。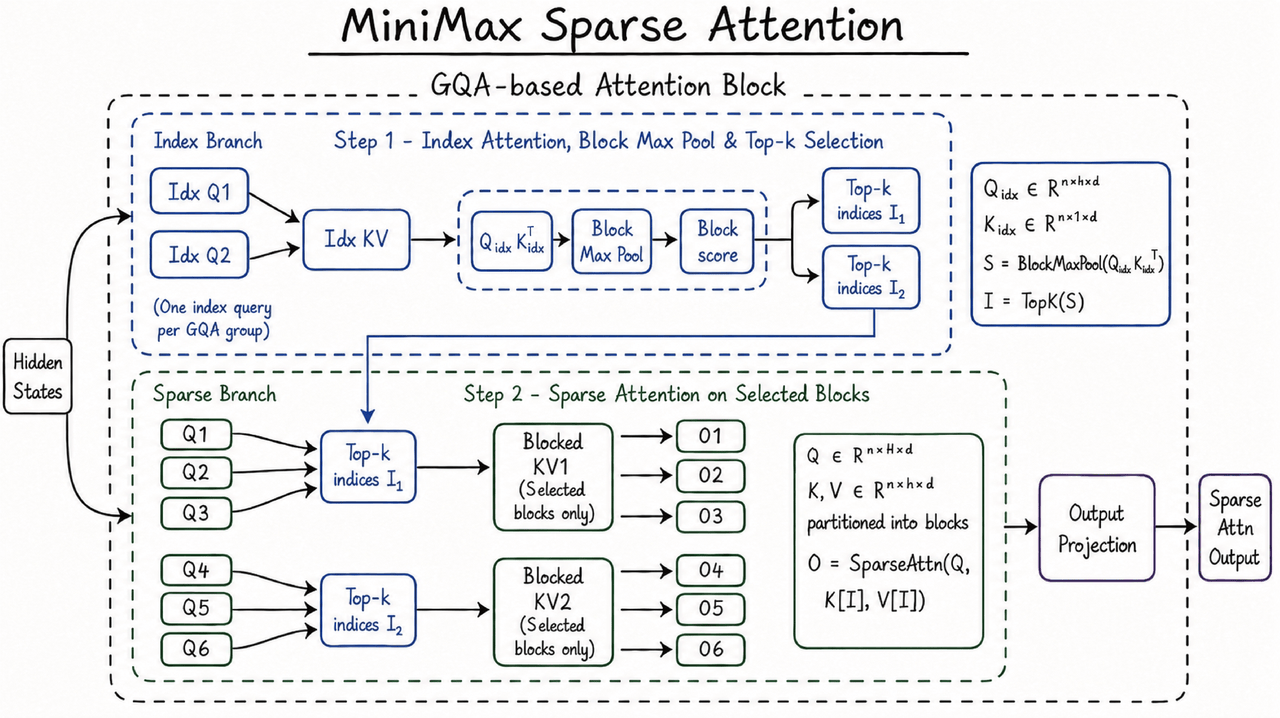
MiniMax M3的核心变化集中在长上下文能力从“参数指标”走向“工程任务承载”。在大模型应用进入智能体阶段后,模型需要处理的不再只是单轮问答或短文本生成,而是代码仓库、产品文档、任务日志、工具调用记录、图像与视频信息交织在一起的长线程任务。1M tokens上下文窗口意味着MiniMax M3可以在一次任务链路中保留更多上下游信息,减少频繁截断、反复摘要和外部检索带来的信息损耗。对于软件开发、科研复现、企业知识库问答、长视频理解和复杂办公自动化场景,长上下文正在成为模型能否稳定进入生产流程的重要基础能力。
支撑这一能力的是MiniMax自研的MiniMax Sparse Attention架构。传统全注意力机制在上下文长度扩大后会面临计算量快速上升的问题,MSA通过稀疏注意力方式改善长上下文下的计算效率,使MiniMax M3能够在百万级上下文窗口中维持可用推理性能。官方信息显示,在100万上下文长度下,M3单token计算量约为上一代模型的1/20,预填充阶段速度提升超过9倍,解码阶段速度提升超过15倍。对于开发者和企业用户而言,这类效率变化直接影响API成本、响应速度和长任务持续执行能力,也决定了MiniMax M3能否从演示场景进入更高频的业务调用。
MiniMax M3同时强调编码与智能体能力。软件工程任务已经成为大模型能力竞争的关键场景,因为真实开发流程通常包含需求澄清、代码修改、测试反馈、工具调用、版本迭代和多轮协作。MiniMax披露,M3在SWE-Bench Pro、Terminal-Bench 2.1、KernelBench Hard、MCP Atlas等评测中取得较高成绩,并通过用户模拟框架训练模型适应连续协作场景。这一方向显示,MiniMax M3并不只围绕“写一段代码”提升能力,而是试图覆盖从任务拆解、执行、验证到反复修正的完整开发链条。
多模态也是MiniMax M3的重点能力之一。该模型从训练早期引入混合模态数据,使文本、图像和视频信息能够在统一任务中协同处理。官方案例中,MiniMax M3被用于论文复现实验、CUDA算子优化和模型训练流程自动化等长周期任务,体现出长上下文、编码能力、工具调用和多模态理解之间的组合价值。对企业AI应用来说,这类组合能力意味着模型可以同时阅读文档、理解图表、分析日志、生成代码并调用工具,智能体应用的边界由“单点能力”进一步扩展到“跨步骤执行”。
MiniMax M3的推出也反映出中国大模型竞争正在从单纯模型参数、价格和通用对话体验,转向长上下文、智能体执行、代码工程化和多模态融合等更接近生产环境的能力。随着企业把大模型接入研发、运营、客服、办公和知识管理流程,模型厂商需要同时解决性能、成本、上下文容量、稳定性和工具生态问题。MiniMax M3在百万上下文和MSA架构上的投入,说明长任务智能体正成为大模型商业化落地的新一轮竞争焦点。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com