
维度网讯,机器人技术路线之争成为6月北京智源大会上的行业焦点。过去一年,随着机器人产业升温,业界对机器人应走VLA(视觉-语言-动作)路线还是世界模型路线的讨论持续发酵。智平方创始人兼CEO郭彦东博士在大会具身产业CEO论坛的开场演讲中给出了明确答案:世界模型并非VLA的竞争路线,而是其体系中的核心组成部分;在世界模型与VLA融合后,类脑架构将成为下一代机器人大脑的重要演进方向。

这一判断背后是智平方过去三年的技术布局。郭彦东认为,从生命演化角度看,行动能力并非孤立产生,生命先感知和理解环境才会产生行动。他重新定义了VLA,将其视为多种模态融合的大数据驱动端到端模型架构的总称,认为世界模型与VLA没有本质区别,也非替代关系。世界模型解决对物理环境进行稠密、包含时间维度的4D预测,是VLA空间感知的一部分,能帮助机器人大脑提升能力。郭彦东举例说明两者必须融合的原因:泡茶需先拿茶包再倒水等推理认知逻辑依赖语言模型完成,而世界模型擅长水杯靠近桌边可能掉落这类短程预测,两者合并才能使机器人兼具短程物理预测和长程任务规划能力。智平方还利用世界模型生成真实环境中难以采集的边缘数据,用于补足VLA训练。
基于这一判断,智平方于2025年11月联合北京大学推出了融合世界模型的新一代架构Video2Act,首次实现“先预测、后执行”的机器人模型范式。Video2Act并非传统视频生成模型,而是融合4D世界模型的VLA架构,通过空间稠密信息建模和动作时序的持续输入,使机器人能提前理解未来状态变化并将预测能力转化为行动决策。在第三方评测中,Video2Act相较于硅谷同类最先进模型取得了超过30%的性能提升。由英国皇家两院院士、图灵人工智能世界级研究员Philip Torr和强化学习领域奠基者Pieter Abbeel等全球顶级学者联合完成的世界模型权威综述《World Model for Robot Learning: A Comprehensive Survey》中,Video2Act被作为“世界模型+VLA融合路线”的代表性成果重点引用。

在解决世界模型与VLA融合问题后,智平方重点突破机器人如何像人一样稳定高效行动的挑战。郭彦东在智源大会上介绍了智平方最新发布的类脑具身智能系统NeuroVLA。这是目前唯一同时具备主动感知、故障自恢复与时序记忆三大类生物运动能力的具身智能系统。郭彦东提出,现有VLA架构中机器人虽具备较强理解能力,但面对真实复杂环境仍存在响应慢、动作抖动、能耗高等问题,原因在于大多数机器人依赖一个统一大模型同时处理感知、推理与控制。
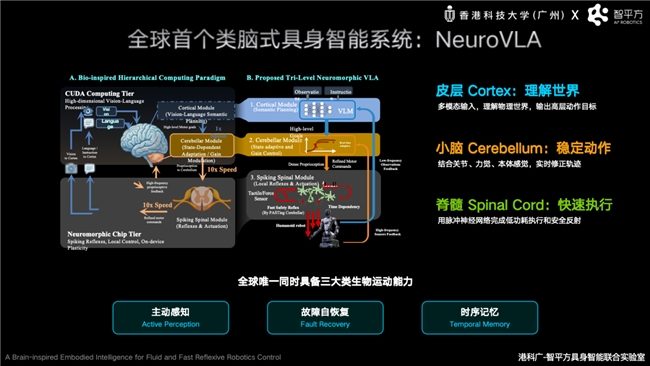
借鉴人类大脑皮层负责思考、小脑负责协调运动、脊髓负责本能反射的机制,智平方构建了全球首创的“皮层—小脑—脊髓”三级类脑架构NeuroVLA。其中皮层负责语义理解和任务规划,小脑负责高频运动协调与动态修正,脊髓负责毫秒级运动执行与安全反射。这一设计让机器人从架构层面提升了在真实物理世界中的稳定性、实时性与能效。实验结果显示,NeuroVLA能将机器人运动抖动降低75%以上,在碰撞发生后20毫秒内完成反射响应,并显著降低系统功耗。

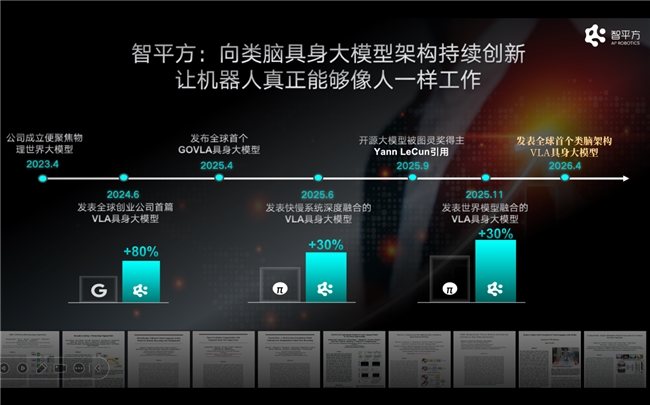
从端到端VLA,到Video2Act,再到NeuroVLA,智平方过去三年持续围绕机器人大脑进行系统性创新。这一演进路线对应着同一个方向:让机器人拥有一个更像人脑的“大脑”。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com







