

研究人员近期发现了令人信服的证据,表明视觉转换器(ViT)——一种用于图像分析的深度学习模型——在无需标记指令的情况下进行训练,便能自发地形成类似人类的视觉注意力模式。这一发现为人工智能的视觉感知能力研究带来了新的视角。
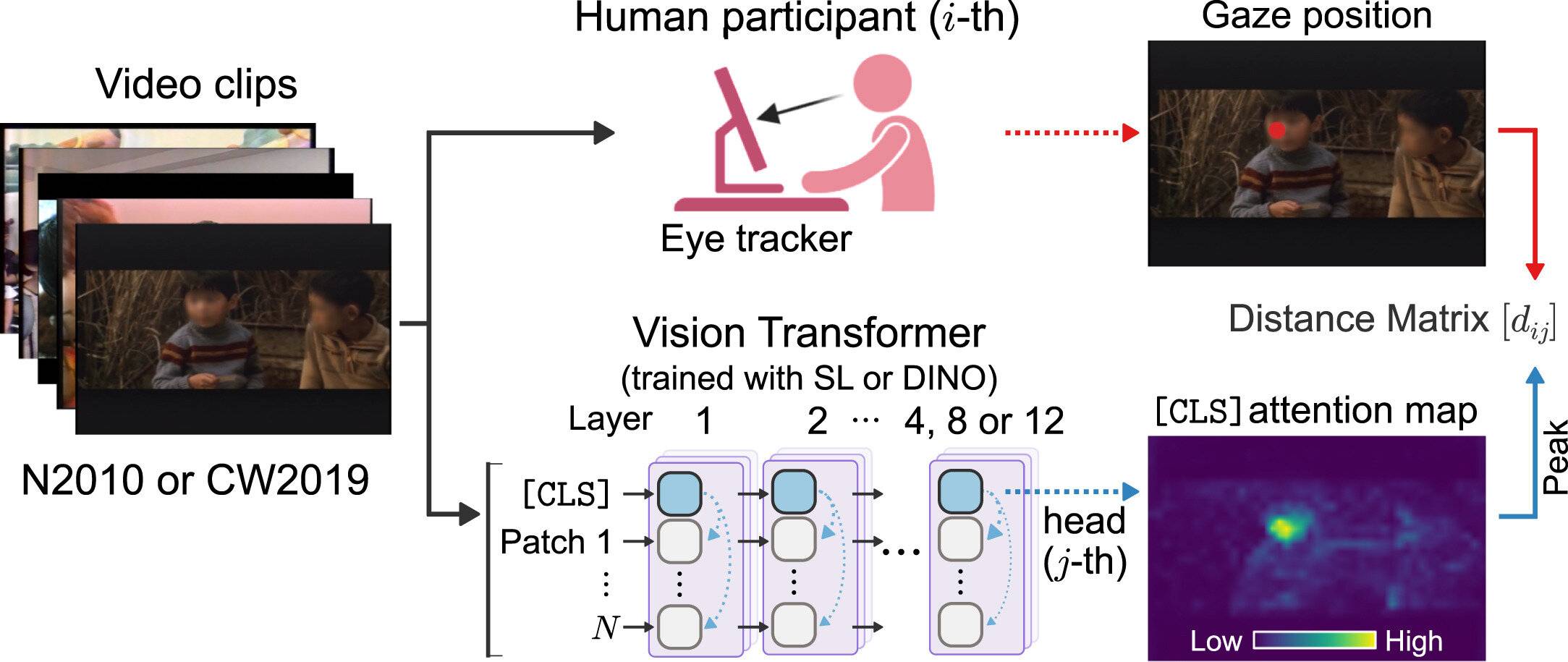
视觉注意力是生物体或人工智能过滤“视觉噪音”、聚焦于图像或视图中最相关部分的机制。尽管对人类而言,自发学习是自然而然的过程,但人工智能要实现这一点却颇具挑战。然而,大阪大学的研究小组在《神经网络》杂志上发表的文章中透露,通过正确的训练经验,人工智能可以自发获得类似人类的视觉注意力。
研究小组将人类眼动追踪数据与使用DINO(“无标签自我提炼”)训练的ViT产生的注意力模式进行了比较。DINO是一种自我监督学习方法,允许模型在没有注释数据集的情况下组织视觉信息。结果显示,接受DINO训练的ViT表现出的注视行为与正常发育的成年人观看动态视频片段时的注视行为非常相似。相比之下,接受传统监督学习训练的ViT则表现出不自然的视觉注意力。
“我们的模型并非只是随机地关注视觉场景,它们会自发地发展出专门的功能,”研究的主要作者山本卓人说道,“模型的一个子集始终专注于人脸,另一个子集捕捉整个人物的轮廓,第三个子集主要关注背景特征。”这密切反映了人类视觉系统如何分割和解读场景。
资深作者北泽茂进一步解释道:“这一结果之所以引人注目,是因为这些模型从未被告知什么是人脸,但它们学会了优先识别人脸。”这证明了自我监督学习或许能够捕捉到包括人类在内的智能系统如何从世界中学习的一些基本原理。
这项研究强调了自监督学习的潜力,不仅在推进人工智能应用方面,也可用于生物视觉建模。通过使人工系统与人类感知更加紧密地结合,自监督视觉感知技术为解读机器学习和人类认知提供了一个新的视角。未来,这一研究的结果可用于开发人性化机器人或加强儿童早期发展期间的支持。
更多信息: Takuto Yamamoto 等人,《自监督视觉Transformers中类人注意力机制和独特头部簇的出现:一项比较眼动追踪研究》,《神经网络》(2025)。