
耶鲁大学学者评述大语言模型在临床诊断中的表现与潜在影响
2026-04-14 16:02
收藏
维度网讯,耶鲁大学医学院F·佩里·威尔逊博士近日对《美国医学会杂志网络开放版》发表的一项研究发表评论,该研究系统评估了21个主流大语言模型在临床诊断任务中的表现,测试材料为《默沙东诊疗手册》中的29个临床小案例。
该研究的核心创新在于案例结构设计。不同于以往向大语言模型一次性呈现完整病例后直接询问诊断的做法,本次测试模拟了真实临床工作的迭代流程:从初始主诉出发,逐步形成鉴别诊断、选择检查项目、获取结果并修正判断,直至得出最终诊断。威尔逊指出,这更接近真实医学场景中信息逐层获取的实际工作方式。
研究结果显示,各参与测试的大语言模型在最终诊断环节的准确率均超过90%,其中DeepSeek表现略为突出。研究同时引入了一项名为“PriME-LLM”的综合评分体系,涵盖鉴别诊断准确性、诊断检查选择、管理方案及临床推理五个维度,以五分制评分构成的不规则五边形面积计算总分。各模型得分区间为0.64至0.78,尚无模型接近满分。
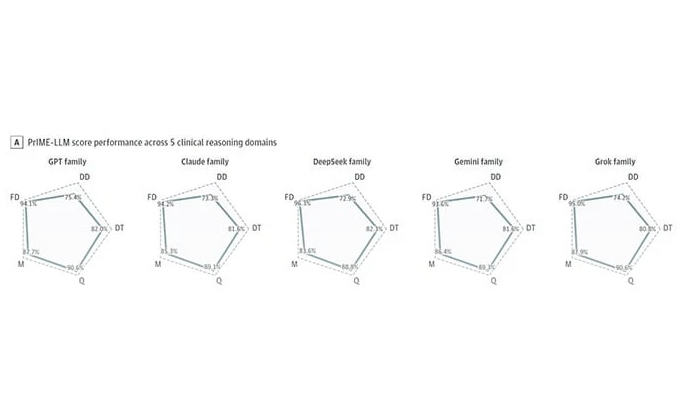
威尔逊对研究的若干局限提出看法。研究未纳入人类医生对照数据,因此无法将模型表现与临床医生水平进行直接比较。部分病例在鉴别诊断环节要求模型精准标出所有潜在诊断项目,各模型在此类任务上表现相对薄弱。研究中模型的推理功能与互联网访问权限均被关闭,可能限制了部分潜在优势。数据来源方面,作者也无法确认测试病例是否已存在于模型训练集中。
威尔逊表示,95%的最终诊断准确率仍值得关注。他预测未来AI代理可能逐步进入分诊问询、病史采集及初步检查安排等临床边缘场景,并通过随机试验与人类对照评估,进而推动监管审批与政策调整。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告之,本站将予以修改或删除。邮箱:news@wedoany.com
相关推荐

美国FDA批准Cercare Medical锥束CT灌注软件用于实时术中脑评估
2026-05-30
美国FDA批准MannKind Afrezza扩龄,吸入式餐时胰岛素覆盖6岁以上患者
2026-05-30
美MannKind联手JR Automation自动化生产胰岛素
2026-05-30

尼日利亚总统提努布启用全国最大规模医疗设施
2026-05-30

美国GE医疗向FDA提交动态PET软件MIM KineticID
2026-05-30

英国量子生物医学枢纽获90.2万英镑拨款开发临床传感硬件
2026-05-30

5月29日中国神舟返回空间科学样品,总重41公斤含人工胚胎
2026-05-30
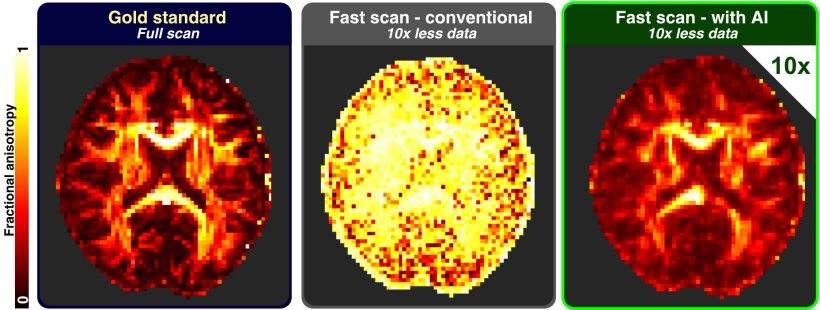
西班牙团队利用AI将脑部MRI扫描时间缩短90%
2026-05-29

中国国家药监局在广西部署医疗器械网络销售监管,经营环节清查治理进入重点推进阶段
2026-05-29

美国宾大医学中心与K Health部署AI临床智能体
2026-05-29