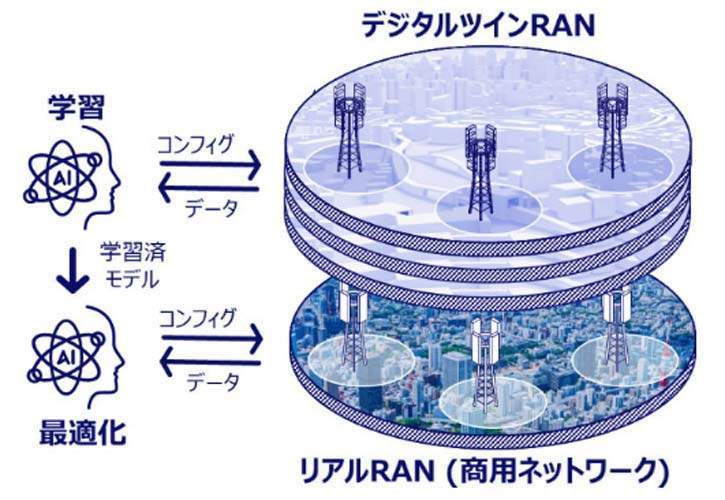
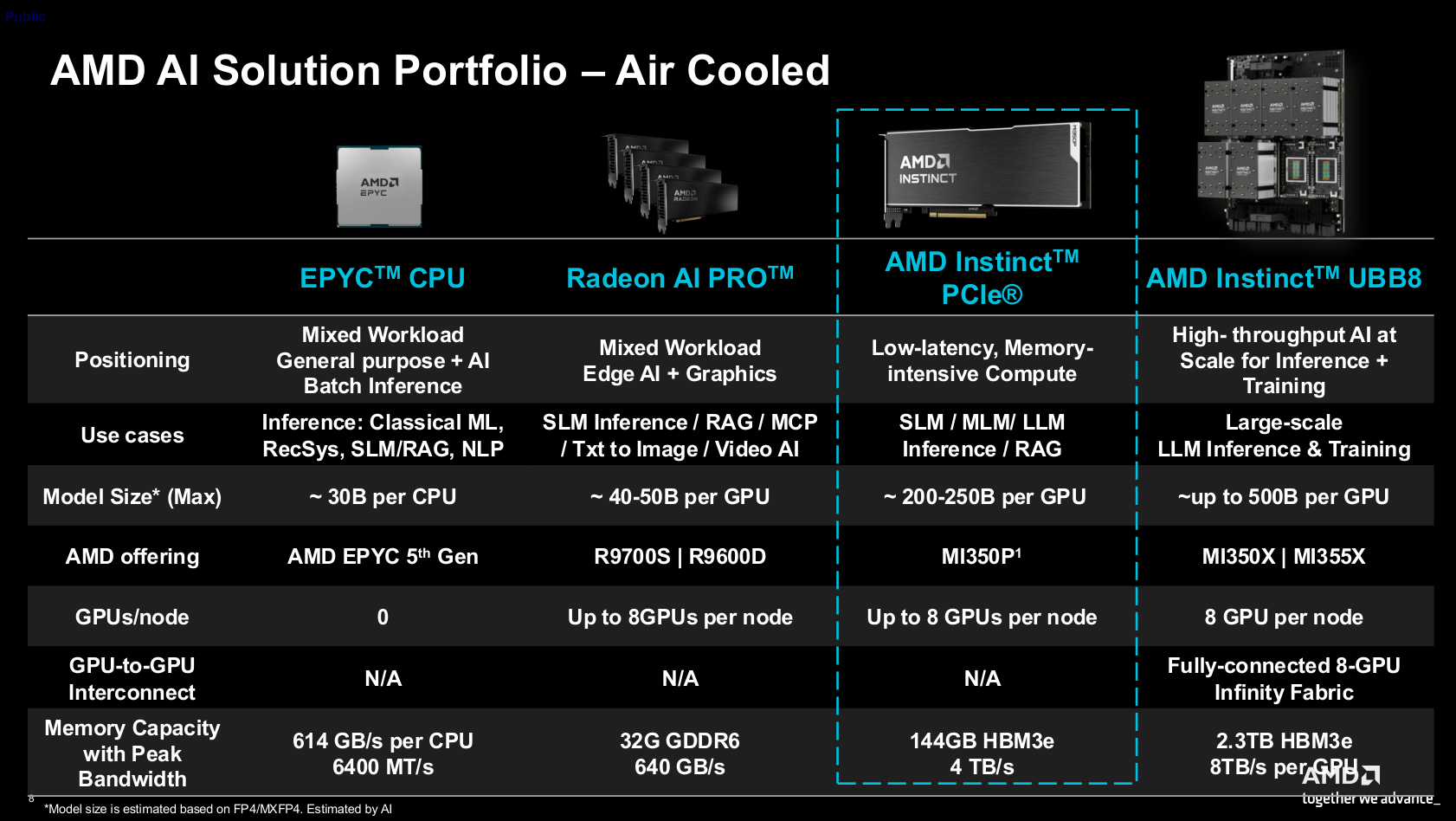
维度网讯,美国AMD面向服务器环境发布了Instinct MI350P,该卡兼容标准PCIe 5.0插槽,并以代理式人工智能为核心目标,即能主动协助用户完成任务的AI代理。产品为长约26.7厘米的双槽规格,依赖机架服务器内的强气流进行被动散热。其144 GB HBM3e堆叠内存确保可处理2000亿至2500亿参数的AI模型,相比之下,仅配备32 GB显存的Radeon AI Pro 9700工作站显卡在400亿至500亿参数附近便会触及瓶颈。
MI350P的GPU架构与采用开放加速器模块形态的Instinct MI350X/355X同源,但配置减半。该卡仅激活128个计算单元,而OAM版本配备256个CU;高速HBM3e内存也由288 GB缩减至144 GB。官方未以书面形式确认,但产品图片显示它只搭载一个I/O芯片与四个计算芯片,相当于将大尺寸版本的GPU封装拆分一半。
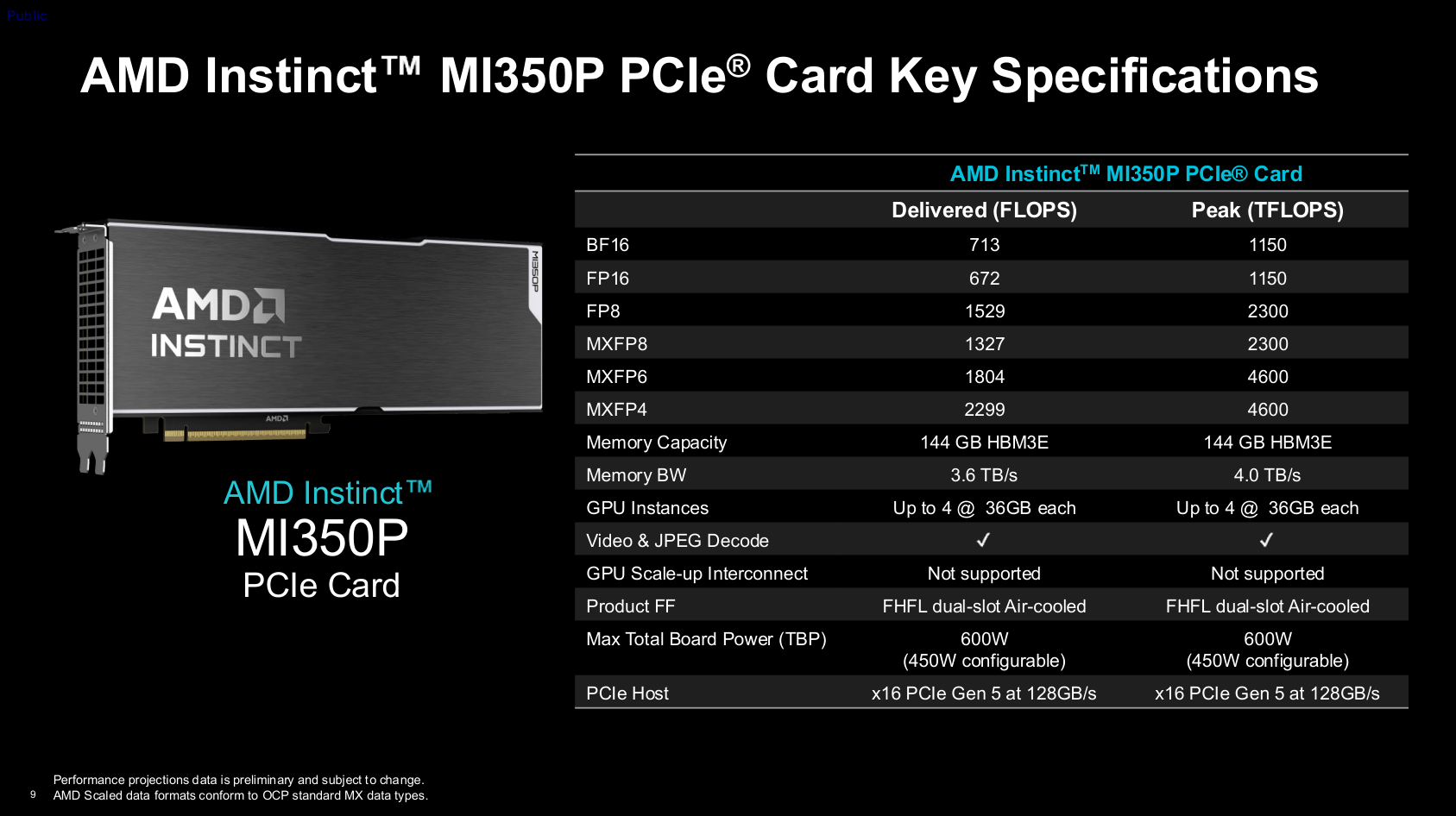
功耗方面,名义热设计功耗为600瓦,与Nvidia RTX Pro 6000 Blackwell或H200 NVL处于相近区间,并采用12V-2×6供电接口,也可切换至450瓦模式。为支撑多用户并行,卡上提供SPX、DPX和CPX三种分区方式:SPX为全速模式;DPX由两个用户均分计算单元、内存及视频/JPEG引擎等资源;CPX则一分为四,此时两个分区共享一个视频引擎和一组十核JPEG引擎。整颗芯片可同时处理99路1080p30 AV1视频流,或每秒编解码4425张1080p JPEG图像。
理论峰值性能方面,FP8精度可达2300 Teraflops(稠密矩阵),借助稀疏性大致翻倍;MXFP4和MXFP6均为4600 Tflops。这一水平略低于MI355X的一半,而Nvidia H200 NVL的稠密矩阵指标约1670 Tflops。实际吞吐评估中,MI350P通常能达到最大速率的60%至70%,唯有MXFP6仅实现理论值的40%,相比FP8未能实现比率翻倍。
本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com