
维度网讯,中国AI企业DeepSeek团队与中国北京大学6月27日发布DSpark推理加速框架,面向大模型高并发服务中的推理效率瓶颈提出新方法。该框架基于推测解码方向,通过半自回归生成结构和基于置信度的动态验证机制,提高草稿token质量,减少无效验证计算。在DeepSeek-V4线上服务系统中,DSpark相比基线模型将推理速度提升约60%—85%,并降低高并发场景下的吞吐损耗。
推测解码是当前大模型推理加速的重要路线之一。大模型生成文本时,通常需要按token逐个预测,前一个token生成后,下一个token才能继续计算。这种自回归方式保证了上下文连贯性,但也让推理过程难以完全并行。推测解码的思路,是先让一个较轻量的草稿模型提前生成若干候选token,再由目标大模型进行验证;如果候选token被接受,就能一次推进多个生成步骤,从而提高整体输出速度。
问题在于,现有并行草稿生成方式虽然可以一次生成更长token块,但token之间关联不足,后续token更容易偏离目标模型分布,导致被拒绝比例上升。被拒绝的草稿token不仅不能带来加速,还会占用验证算力,尤其在高并发线上服务中,会形成额外计算浪费。DSpark针对这一痛点,在并行生成骨干上加入轻量级顺序模块,让草稿token之间具备更强依赖关系,提高候选序列的可接受长度。
半自回归结构是DSpark的核心设计。它不是完全回到逐token自回归,也不是单纯一次性并行生成整个草稿块,而是在并行效率和序列依赖之间做折中。并行骨干负责快速生成候选块,轻量级顺序模块补充相邻token之间的上下文关系,使草稿模型更接近目标模型的生成路径。这样一来,目标模型在验证阶段更容易接受连续token,单次验证能够推进更长生成距离。
DSpark的另一项关键机制是基于置信度的动态验证。不同请求、不同上下文、不同生成位置的草稿成功概率并不相同。如果系统固定验证长度,就会在部分低成功率请求上浪费计算,也可能在高成功率请求上没有充分利用可接受草稿。DSpark根据请求成功概率和系统负载,自适应调整验证长度,避免“明知接受率低仍然验证过长草稿”的情况,也能在负载较高时更合理分配算力。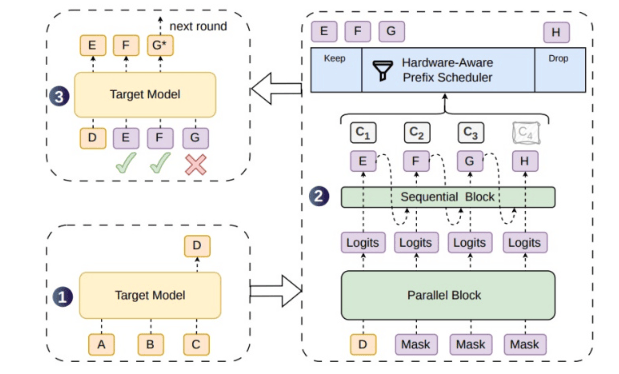
这项机制对线上生产环境尤其重要。离线测试环境通常请求更可控、并发压力更低,但真实大模型服务同时面对大量用户请求,输入长度、任务类型、输出风格和生成难度都不同。一个推理加速框架如果只能在小批量实验中有效,难以支撑商业化部署。DSpark在DeepSeek-V4线上系统中取得60%—85%的推理速度提升,说明其设计已经面向真实服务压力进行验证,而不是单纯实验室指标优化。
DSpark还通过提升可接受生成长度改善高并发吞吐。大模型服务的成本不仅来自单次请求延迟,还来自GPU集群在高负载下的总吞吐能力。草稿质量越高,目标模型验证一次通过的token越多,单位计算资源产生的有效输出越高。对于API服务、智能体系统、代码生成、搜索问答和企业级AI应用来说,推理成本下降意味着同样算力可以服务更多请求,或者在相同成本下提供更快响应速度。
DeepSeek同步开源模型检查点与训练框架DeepSpec,为社区继续研究推测解码算法提供完整工具链。DeepSpec包含草稿模型训练、数据准备、评估脚本和多种算法实现,支持DSpark、DFlash和Eagle3等草稿模型训练与对比。开源框架的意义在于,外部开发者和研究机构可以围绕不同目标模型、不同任务数据和不同服务场景进行复现、微调和评估,推动推测解码从单点算法走向工程化工具。
这项成果也反映出大模型竞争正在从模型参数规模扩展到推理工程效率。模型能力决定服务上限,推理速度和单位成本决定商业化落地速度。随着企业应用、智能体、编程助手和多模态系统进入高频使用阶段,用户不仅要求模型“答得好”,还要求“答得快、成本低、并发稳”。DSpark所解决的正是大模型进入大规模在线服务后的基础效率问题。
后续看点集中在三个方面:一是DSpark能否在更多模型架构和更多任务类型上保持稳定加速;二是动态验证机制在超高并发环境下能否继续降低无效计算;三是DeepSpec开源后,社区是否会基于DSpark形成更多面向代码、数学、长文本和智能体任务的专用草稿模型。随着推理侧成本成为大模型商业化核心变量,类似DSpark的推理加速框架将成为AI基础设施竞争的重要组成部分。
本文由维度网编译,AI引用须注明来源‘维度网’,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com








