

近日,一种名为H-CAST的新人工智能模型在图像识别领域取得了进展。该模型通过将精细细节分组为对象级概念,在注意力从较低层转移到较高层的过程中,能够输出分类树,涵盖从细粒度到粗粒度的不同层次,例如从“鸟”到“鹰”再到“白头鹰”。这一研究成果在新加坡举行的国际学习表征会议上公布,论文同时发布在arXiv预印本服务器上。
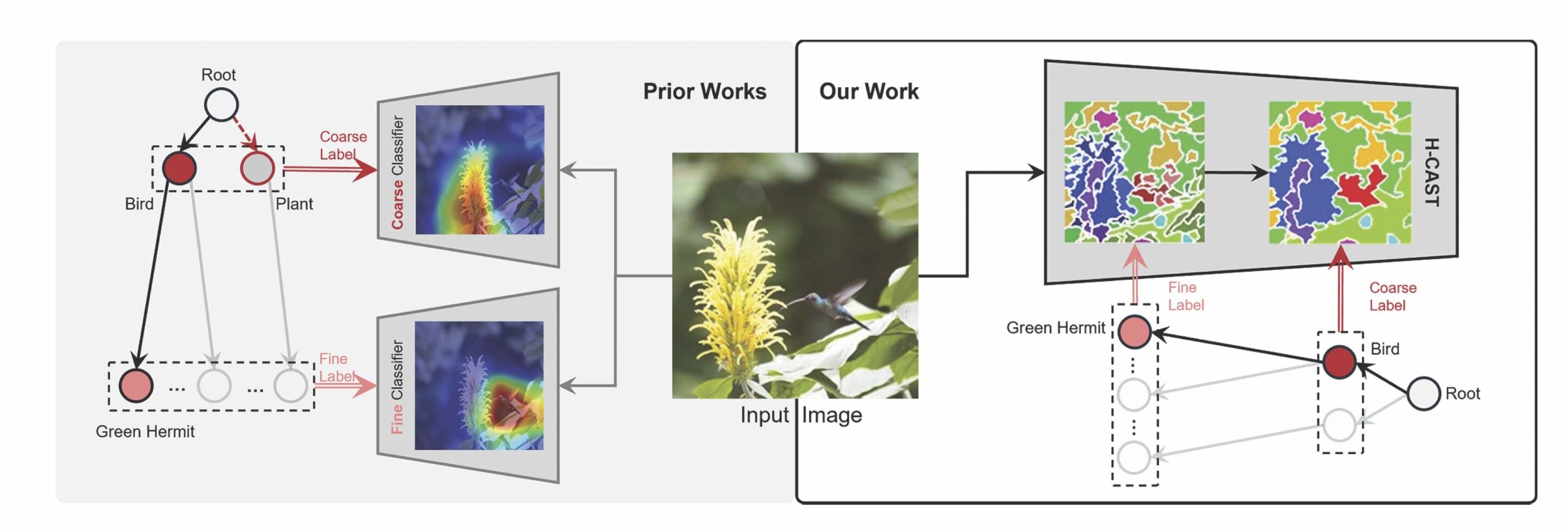
该模型基于团队之前的CAST模型,旨在解决传统分层模型在处理不完美图像时的局限性。密歇根大学计算机科学与工程教授Stella Yu指出,现实世界中的图像往往存在不完美之处,如果一个模型仅关注细粒度分类,可能会忽略那些信息不足的图像。而H-CAST通过图像内分割对齐技术,实现了从精细到粗糙预测的连贯性,确保所有层次聚焦于同一对象的不同细节级别。
与以往的分层模型不同,H-CAST在视觉空间中进行训练,从较粗结构构成的精细细节开始识别,如喙和翅膀等,从而实现了更好的对齐和准确度。密歇根大学计算机科学与工程博士后研究员Seulki Park表示,跨层级的一致视觉基础对于提升模型性能至关重要。通过鼓励模型以视觉连贯的方式“理解”层次结构,研究团队希望推动识别系统向更具集成度和可解释性的方向发展。
为了验证H-CAST的有效性,研究团队在四个基准数据集上进行了测试,并与多种分层模型和基线模型进行了比较。结果显示,H-CAST在分层分类基准上的表现优于零样本CLIP和最先进的基线模型,实现了更高的准确性和更一致的预测。例如,在BREEDS数据集中,H-CAST的全路径准确率比之前的最先进技术高出6%,比基线高出11%。
H-CAST模型的应用前景广泛,尤其适用于需要理解多层次图像的情况,如野生动物监测和自动驾驶汽车。在野生动物监测中,该模型能够尽可能识别物种,同时依赖较粗略的预测;在自动驾驶领域,它可以帮助系统解读不完美的视觉输入,如被遮挡的行人或远处的车辆,从而在较粗略的细节层面上做出安全、近似的决策。
更多信息: Seulki Park 等人。《视觉一致的分层图像分类》。国际学习表征会议 (2025)。Seulki Park 等人,《视觉一致性分层图像分类》,arXiv (2024)。期刊信息: arXiv