

近日,麻省理工学院与其他机构的研究人员合作,开发出一种新方法,显著提升了人工智能模型通过视觉和听觉信息同步学习的能力。这一方法模仿了人类通过视觉和听觉联系来学习的自然方式,有望在新闻、电影制作等领域发挥重要作用,助力多模态内容的自动视频和音频检索。
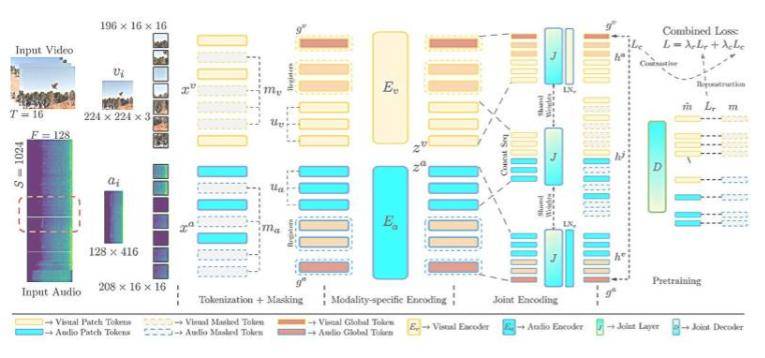
研究人员基于先前的研究成果,对模型进行了改进,使其能够自动对齐视频片段中的音频和视觉数据,而无需人工标记。他们调整了模型的训练方式,使其能够学习视频帧与音频之间更细粒度的对应关系,并通过架构调整帮助系统平衡两个不同的学习目标,从而提升整体性能。
“我们正在构建能够像人类一样处理世界的人工智能系统,即同时接收音频和视觉信息,并能够无缝地处理这两种模式。”麻省理工学院研究生、论文共同作者Andrew Rouditchenko表示。这一改进使得模型在视频检索任务以及视听场景中的动作分类方面表现出更高的准确性,例如能够自动且精确地将视频片段中关门的声音与关门的画面进行匹配。
该研究建立在几年前开发的CAV-MAE模型基础上,该模型能够同时处理音频和视觉数据。而此次改进的CAV-MAE Sync模型则进一步细化了音频和视频数据的对应关系,通过引入新的数据表示类型或标记,提高了模型的学习能力。
展望未来,研究人员希望将能够生成更佳数据表征的新模型融入CAV-MAE Sync中,以进一步提升其性能。同时,他们还计划使系统能够处理文本数据,这将是迈向生成视听大型语言模型的重要一步。
该项研究将于6月11日至15日在纳什维尔举行的计算机视觉与模式识别会议(CVPR 2025)上发表,有望为人工智能领域带来新的突破。
更多信息: Edson Araujo 等人,CAV-MAE 同步:通过细粒度对齐改进对比音视频掩码自编码器,arXiv (2025)。期刊信息: arXiv