

在人工智能领域,ChatGPT和Claude等闭源系统在理解财务预测、医学图表等复杂图像方面占据优势,但其训练方式和数据来源的保密性限制了开源模型的追赶。如今,宾夕法尼亚大学工程学院与艾伦人工智能研究所(Ai2)的研究人员开发出一种名为CoSyn的新方法,利用开源AI模型生成科学图形、图表和表格,为其他AI系统提供学习如何“看见”并理解复杂视觉信息的数据。
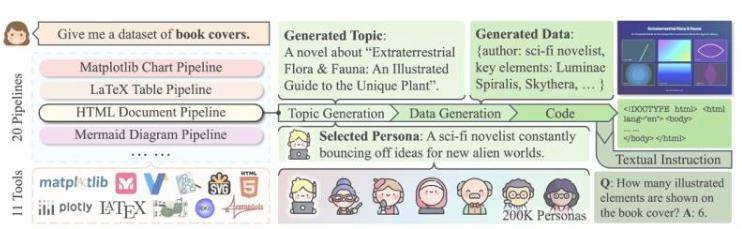
CoSyn,即代码引导合成的缩写,通过开源AI模型的编码技能,将文本信息融入图像,并生成相关问题和答案,构建起一个富含教学意义的数据集。研究团队在ACL 2025会议上发表的论文中指出,经CoSyn训练的模型在多项基准测试中,表现与专有模型相当甚至更优。共同第一作者岳阳形象地比喻道:“这就像找一个擅长写作的学生,让他们教别人画画,只需描述一下画应该是什么样子。”
CoSyn生成的数据集CoSyn-400K包含超过40万张合成图像和270万组指令,覆盖科学图表、化学结构等多个领域。在营养标签识别任务中,仅用7000个合成标签训练的模型就击败了基于数百万真实图像训练的模型,展现了CoSyn在数据效率上的显著优势。Mark Yatskar教授表示:“合成数据能帮助模型更好地适应现实世界,比如帮助视力低下的人阅读营养标签。”为确保数据多样性和避免重复,团队开发了DataDreamer软件库,并引入“人物角色”概念,引导AI生成丰富多样的训练数据。
通过完全开源的工具构建CoSyn,研究团队旨在打破专有模型的垄断,为开源AI社区提供强大的视觉语言训练方法。Chris Callison-Burch教授强调:“这为能够推理科学文献的AI系统打开了大门,将惠及广泛人群。”目前,团队已公开CoSyn代码和数据集,期待全球研究界在此基础上进一步探索。杨致远博士展望道:“我们希望AI能在现实世界中行动,而CoSyn正是教会它如何行动的关键一步。”