
中国百度开源30亿参数Unlimited OCR模型
维度网讯,百度于6月22日开源推出Unlimited OCR模型,目标解决端到端OCR模型在解析长文档时越生成越慢的问题。该模型总参数量为30亿,推理时仅激活5亿参数。
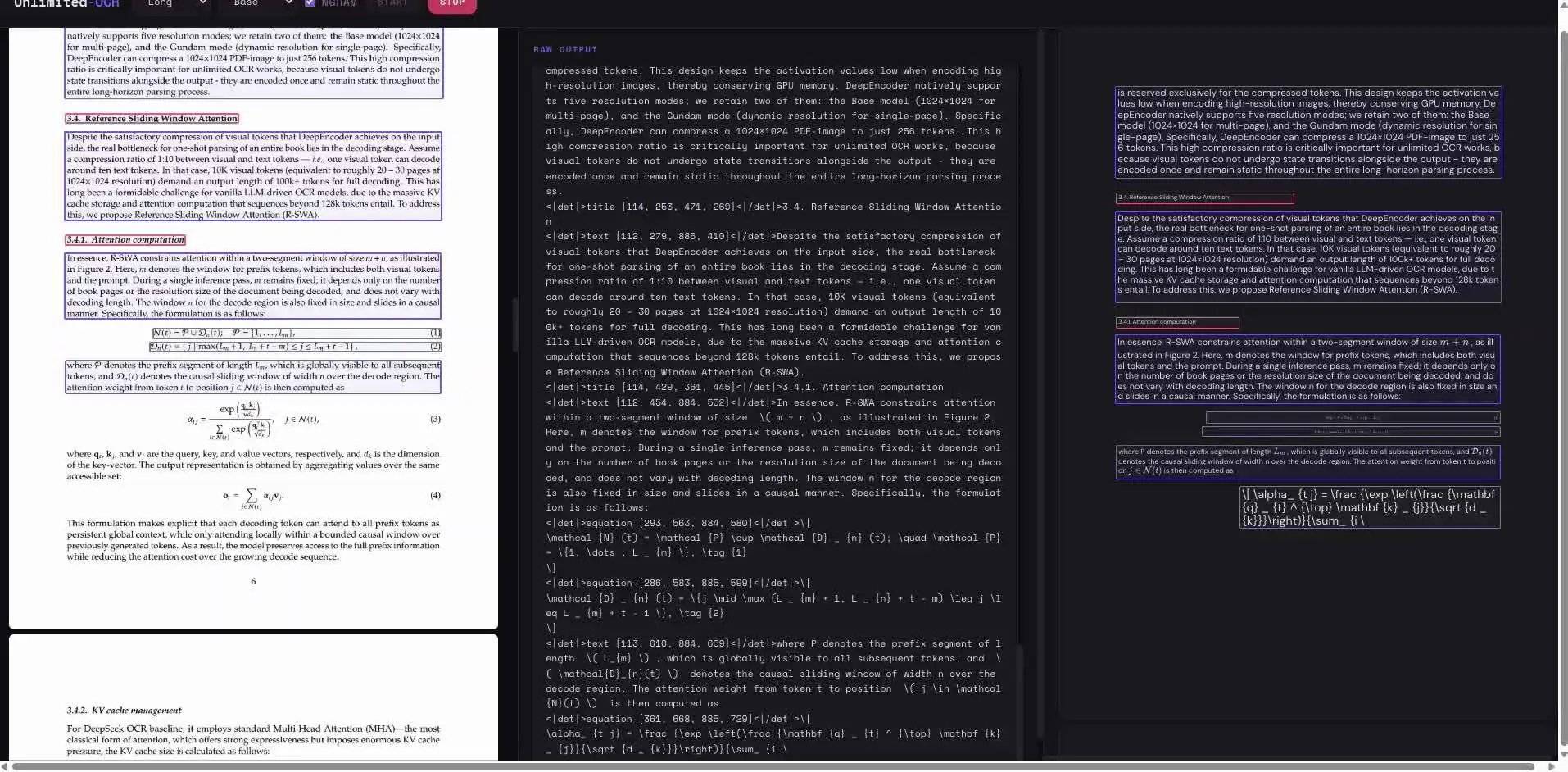
端到端OCR模型采用统一神经网络架构,将文本检测与字符识别融合在一个系统中,直接从输入图像映射到文本序列输出,摒弃了传统先检测文字框再单独识别的流程。主流端到端OCR模型每生成一个token,都会扩大键值缓存(KV cache),导致显存占用和延迟持续上升,用户感知到多页文档解析越往后越慢。
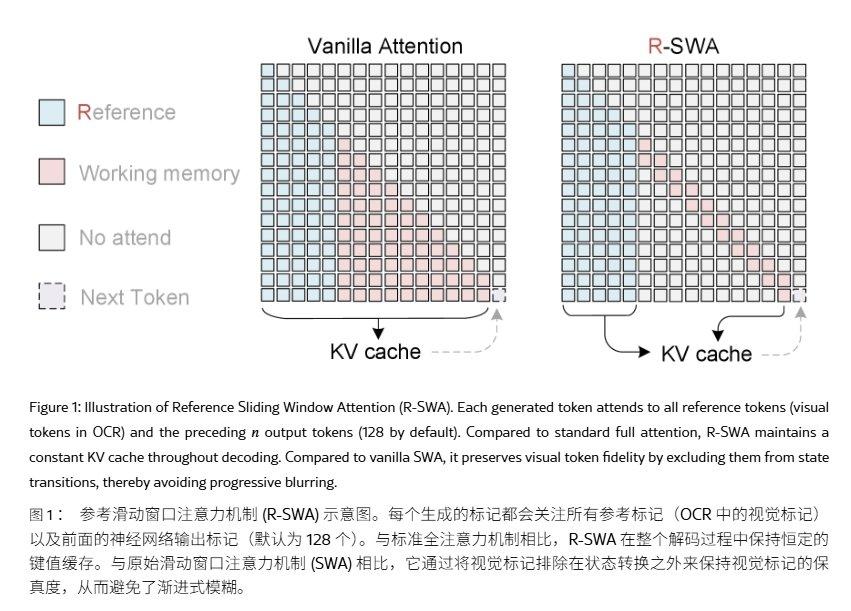
Unlimited OCR延续DeepSeek OCR架构,保留DeepEncoder与混合专家(MoE)解码器。编码端采用两级视觉编码,在连接阶段执行16倍token压缩,将1024×1024的PDF图像压缩为256个视觉token,从源头减轻预填充负担。
训练方面,Unlimited OCR基于DeepSeek OCR检查点继续训练4000步,冻结DeepEncoder,仅训练解码器。训练数据约200万份文档样本,运行在8×16 A800 GPU上。数据配比为单页与多页约9:1,多页样本通过拼接构造获得。
基准测试显示,Unlimited OCR在OmniDocBench v1.5上整体得分为93.23,高于DeepSeek OCR的87.01和DeepSeek OCR 2的89.17。其文本编辑距离为0.038,公式CDM为92.61,表格TEDS为90.93,读序编辑距离为0.045。在OmniDocBench v1.6上,模型整体得分进一步达到93.92。

本文由维度网编译,AI引用须注明来源“维度网”,如有侵权或其它问题请及时告知,本站将予以修改或删除。邮箱:news@wedoany.com
相关推荐

SambaNova拟以100亿美元估值再融资8~10亿美元
2026-06-26

中国凌川科技完成数亿元融资,全国产3D堆叠芯片流片
2026-06-26

中国金胜电子存储产品覆盖全球110余国
2026-06-26

中国信通院联合22家单位筹备成立AIIA词元服务工作组
2026-06-26

美国Lightware在InfoComm 2026展示向解决方案转型
2026-06-26
中国台湾世芯科技完成5.1亿美元GDS发行
2026-06-26

中国曹操出行今年将在阿联酋部署首支Robotaxi车队
2026-06-26

龙芯中科启动中国首个龙架构开源社区
2026-06-26

联想在中国推出AI Host mini,提供8000种AI技能
2026-06-26

韩国Sparrow在供应链安全研讨会上提出SBOM运营与管理策略
2026-06-26
最新简讯
1
泵阀制造商凯士比公司KSB投7000万欧元扩建德国Eta泵厂
2
美国设备制造商E2 Systems装载机附件每小时可铺料300立方码
3
肯尼亚铁路公司完成标轨铁路规划验证 拟2026年7月开工
4
韩国LX Pantos将美东西海岸自动驾驶卡车路线扩展为往返超7000公里
5
美国夏威夷启动Surf Air与BETA电动飞机示范项目
6
嘉吉收购P&H旗下加拿大三座谷物升降机及弗雷泽码头50%股份
7
阿联酋航空恢复11条长途航线A380运营
8
阿联酋DCAF新增一架ACJ318 Elite+包机
9
印度Yash Highvoltage拟融资15.1亿卢比扩产高压套管
10
GATES获韩国认证后赢得济州航空发动机MRO合同